Use pickle to create API service

i have python code recipe that already create the pickle model and save the pickle to filesytem_folder and already in scenario for weekly pickle update. then i want to create api that use this pickle to classify. i use Custom prediction (Python) for Endpoint type and set the Working folder (optional) to the filesytem_folder where the pickle saved. but until now i cannot get the pickle.
in this line:
with open(file_path, 'rb') as f:
self.model = pickle.load(f)
i got this error:
Can't get attribute 'ImpulseDetector' on <module 'dataiku.apinode.predict.customserver' from '/dss_data/dataiku-dss-13.1.2/python/dataiku/apinode/predict/customserver.py'>
any sample that use pickle in filesytem_folder for create api service?
Best Answers
-
 Alexandru Dataiker, Dataiku DSS Core Designer, Dataiku DSS ML Practitioner, Dataiku DSS Adv Designer, Registered Posts: 1,399 Dataiker
Alexandru Dataiker, Dataiku DSS Core Designer, Dataiku DSS ML Practitioner, Dataiku DSS Adv Designer, Registered Posts: 1,399 DataikerHi,
The AttributeError happens because the pickle file only contains the data and a reference to its class, not the class itself. The API node environment doesn't have the ImpulseDetector class definition.
Can you try to either
1) Add the Class to the Script Copy the entire class ImpulseDetector: block from your training recipe and paste it into your API endpoint's Python script, right above your MyPredictor class.2) Use Project Libraries. Place the ImpulseDetector class in your project's Library. In both your training recipe and your API endpoint script, import it using from my_library_file import ImpulseDetector.
Let us know if that helps -
the solution 1 is not work. the error is still the same. i dont know why it not detect the class in the code API endpoint's Python script.
for solution 2. there is step by step. so i do it correctly. because currently my project libraries is default like this:

Answers
-
Alexandru Dataiker, Dataiku DSS Core Designer, Dataiku DSS ML Practitioner, Dataiku DSS Adv Designer, Registered Posts: 1,399 Dataiker
Hi,
The structure of your code doesn't seem correct for a custom prediction endpoint:
https://doc.dataiku.com/dss/latest/apinode/endpoint-python-prediction.html#structure-of-the-code
Here is an example of using pickle file from an attached folder in an API endpoint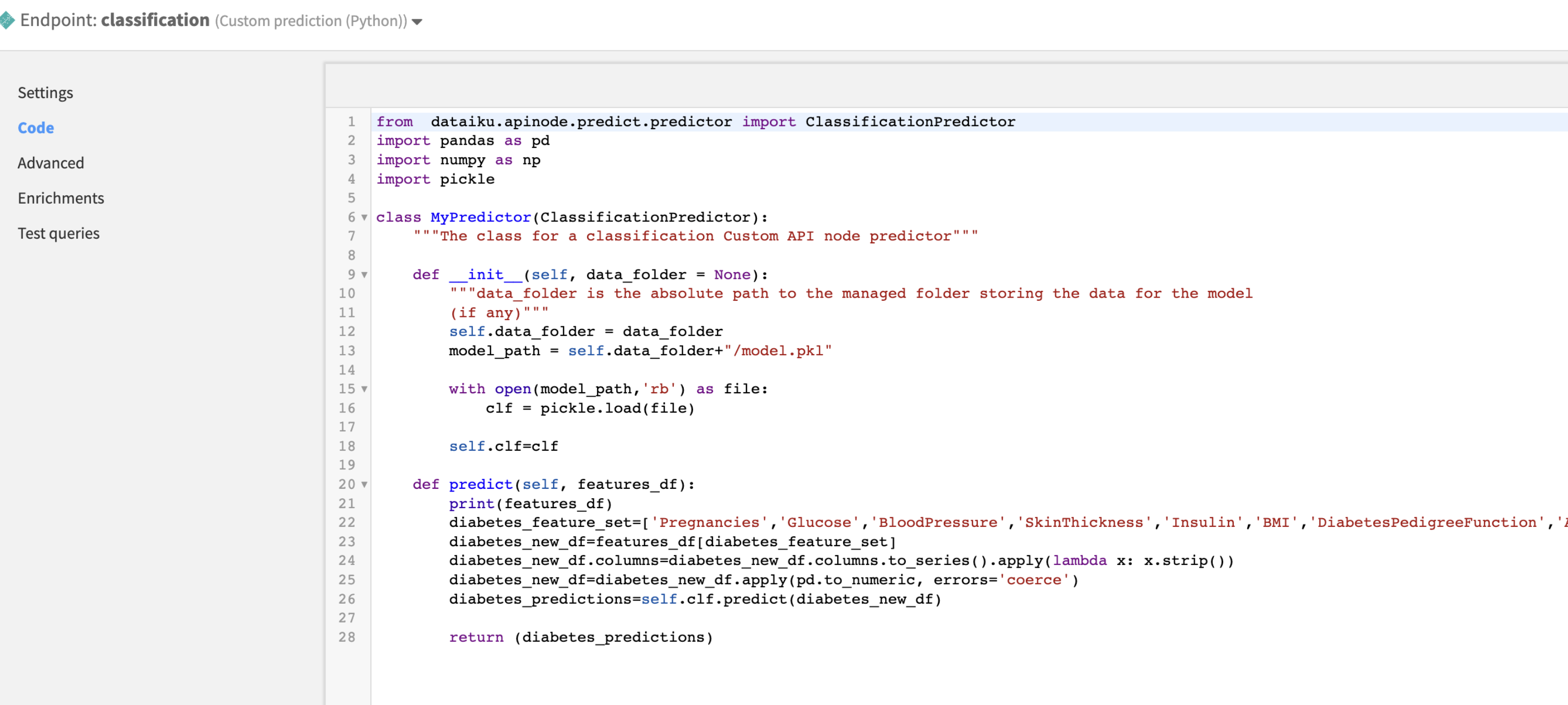
Kind Regards, -
okey, let me start again.
so i have python recipe that create/train the pickle and the code already works.
here is recipe and run in py 3.8 env:
and here the code in the recipe:
import os
import dataiku
import pandas as pd, numpy as np
from dataiku import pandasutils as pdu
from datetime import datetime, timedelta
import pickle
# Read recipe inputs
v_infa_dynamic_monitoring = dataiku.Dataset("v_infa_dynamic_monitoring")
v_infa_dynamic_monitoring_df = v_infa_dynamic_monitoring.get_dataframe()[['ds','end_time','table_target','source_row','target_row','status','mode','ds_job']]
v_infa_dynamic_monitoring_df
# -------------------------------------------------------------------------------- NOTEBOOK-CELL: CODE
# 1. Your input DataFrame
df = v_infa_dynamic_monitoring_df
# 2. Define date filter
ninety_days_ago = datetime.now() - timedelta(days=90)
# 3. Convert `end_time` column to datetime if it’s not already
df['end_time'] = pd.to_datetime(df['end_time'])
# 4. Filter the data
filtered_df = df[
(df['status'].isin(['TRUE', 'WARNING'])) &
(df['end_time'] >= ninety_days_ago)
].copy()
# filtered_df = filtered_df[filtered_df['table_target'] == table_target_test]
# 5. Add `ds_valid` column
filtered_df['ds_valid'] = filtered_df.apply(
lambda row: row['ds'] if 'overwrite' in str(row['mode']).lower()
else row['ds_job'] if 'append' in str(row['mode']).lower()
else row['ds'],
axis=1
)
# 6. Select and reorder columns as in SQL
df_pd_recent_90_days = filtered_df[[
'ds', 'end_time', 'table_target', 'source_row', 'target_row',
'status', 'mode', 'ds_job', 'ds_valid'
]].sort_values(by='end_time', ascending=False).reset_index(drop=True)
# df_pd_recent_90_days[df_pd_recent_90_days['ds_valid']=='anomaly']
df_pd_recent_90_days['ds_valid'] = pd.to_numeric(df_pd_recent_90_days['ds_valid'], errors='coerce')
df_pd_recent_90_days = df_pd_recent_90_days.dropna(subset=['ds_valid'])
df_pd_recent_90_days['ds_valid'] = df_pd_recent_90_days['ds_valid'].astype(int)
df_pd_recent_90_days
# -------------------------------------------------------------------------------- NOTEBOOK-CELL: CODE
# 1. Keep only the latest row for each ds_valid (based on end_time)
df_sorted = df_pd_recent_90_days.sort_values(['table_target','ds_valid', 'end_time'], ascending=[True,True, False])
df_ds_valid_last = df_sorted.drop_duplicates(subset=['table_target','ds_valid'], keep='first')
df_ds_valid_last
# -------------------------------------------------------------------------------- NOTEBOOK-CELL: CODE
# Step 1: Filter table_target groups with at least 20 rows
table_counts = df_ds_valid_last["table_target"].value_counts()
valid_tables = table_counts[table_counts >= 20].index
df_ds_valid_last_ = df_ds_valid_last[df_ds_valid_last["table_target"].isin(valid_tables)]
df_ds_valid_last_
# -------------------------------------------------------------------------------- NOTEBOOK-CELL: CODE
# Ensure ds_valid is treated as a comparable type (e.g., integer or datetime)
df_ds_valid_last_["ds_valid"] = pd.to_numeric(df_ds_valid_last_["ds_valid"], errors="coerce")
# Get the latest rows for each table_target based on ds_valid
df_latest_train = (
df_ds_valid_last_
.sort_values("ds_valid", ascending=False)
.groupby("table_target", group_keys=False)
.head(39)
)
df_latest_train=df_latest_train.sort_values(['table_target','ds_valid'], ascending=[True,False])
df_latest_train
# -------------------------------------------------------------------------------- NOTEBOOK-CELL: CODE
class ImpulseDetector:
def __init__(self):
self.result_df_2d = None # Will store mean/std per table_target
def fit(self, df: pd.DataFrame):
def stat_value(group):
mean_40 = group['target_row'].mean()
std_40 = group['target_row'].std()
group['mean_long'] = mean_40
group['std_long'] = std_40
return group
result_df = df.groupby('table_target', group_keys=False).apply(stat_value)
self.result_df_2d = (
result_df
.groupby('table_target')
.head(1)
.reset_index(drop=True)[['table_target', 'mean_long', 'std_long']]
)
def fitted(self, stat_df: pd.DataFrame):
# Validate required columns exist
required_cols = {'table_target', 'mean_long', 'std_long'}
if not required_cols.issubset(stat_df.columns):
raise ValueError(f"Input DataFrame must contain columns: {required_cols}")
self.result_df_2d = stat_df.copy()
def compute_pulse_flags(self, group, mean_col='mean_long', std_col='std_long',
flag_col='flag_sudden_impulse', ratio_col='impulse_ratio', ratio_val='impulse_value'):
mean = group[mean_col]
std = group[std_col]
with np.errstate(invalid='ignore', divide='ignore'):
upper = mean + 2.2 * std
lower = mean - 2.2 * std
upper_percent = 0.53 * mean*2
lower_percent = 0.47 * mean*2
pulse_ratio = ((abs(group['target_row'] - mean) - 2 * std) / std).clip(lower=0)
pulse_ratio = pulse_ratio.replace([np.inf, -np.inf], -1).fillna(0)
pulse_value = abs(group['target_row'] - mean)
group[ratio_col] = pulse_ratio
group[ratio_val] = pulse_value
group[flag_col] = (
((group['target_row'] > upper) & (group['target_row'] > upper_percent)) |
((group['target_row'] < lower) & (group['target_row'] < lower_percent))
)
return group
def predict(self, df: pd.DataFrame) -> pd.DataFrame:
"""
Merges df with precomputed mean/std and computes impulse flags
"""
if self.result_df_2d is None:
raise ValueError("Model must be fit first with .fit() before prediction.")
merged = df.merge(self.result_df_2d, on='table_target', how='left')
return self.compute_pulse_flags(merged)
# -------------------------------------------------------------------------------- NOTEBOOK-CELL: CODE
detector = ImpulseDetector()
detector.fit(df_latest_train) # -------------------------------------------------------------------------------- NOTEBOOK-CELL: CODE
data = pd.DataFrame({
'table_target': ['0000_staging_as4_lnflag', '0000_staging_as4_lnflag', '000_jke_1500_1011_atm_zona','000_jke_1500_1011_atm_zona','0000_staging_as4_lnflag'],
'target_row': [900000, 100000, 1000,1901,1901]
})
# Now you can predict using the precomputed stats
result = detector.predict(data)
result # -------------------------------------------------------------------------------- NOTEBOOK-CELL: CODE
csv_file_path = os.path.join(folder_path, "stat.csv")
detector.result_df_2d.to_csv(csv_file_path, index=False)
# -------------------------------------------------------------------------------- NOTEBOOK-CELL: CODE
# Write recipe outputs
new_pickle = dataiku.Folder("HKWgLYbz")
folder_path = new_pickle.get_path()
pickle_file_path = os.path.join(folder_path, "impulse_detector.pkl")
# Save model to pickle
with open(pickle_file_path, "wb") as f:
pickle.dump(detector, f)from this i have already get the pickle in the folder:
then i want to use it for create api service. used Custom prediction (Python) for Endpoint type and set the Working folder (optional) to "pickle_folder". here is the setting:
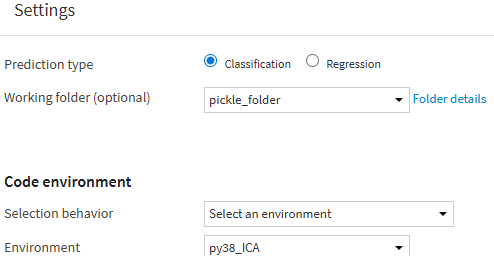
and here is my code:
from dataiku.apinode.predict.predictor import ClassificationPredictor
import pandas as pd
import numpy as np
import pickle
class MyPredictor(ClassificationPredictor):
"""The class for a classification Custom API node predictor"""
def __init__(self, data_folder = None):
"""data_folder is the absolute path to the managed folder storing the data for the model
(if any)"""
self.data_folder = data_folder
model_path = self.data_folder+"impulse_detector.pkl"
with open(model_path,'rb') as file:
detector = pickle.load(file)
self.detector=detector
def predict(self, features_df):
features_df["target_row"] = features_df["target_row"].astype(int)
result_df = self.detector.predict(features_df)
row = result_df.iloc[0]
flag = bool(row['flag_sudden_impulse'])
decision_series = pd.Series([flag])
# Empty probability DataFrame (required by interface)
proba_df = pd.DataFrame()
return decision_series, proba_dfbut i got error:
Can't get attribute 'ImpulseDetector' on <module 'dataiku.apinode.predict.customserver' from '/dss_data/dataiku-dss-13.1.2/python/dataiku/apinode/predict/customserver.py'>
here is the detail log: -
i have try the solution 2 but also have the same error happen nothing changes
here is my library project: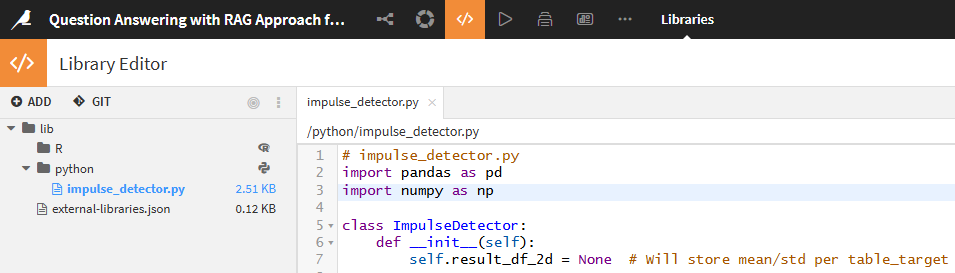
here is my class in py file:
and i add
from impulse_detector import ImpulseDetector
in api code. -
Alexandru Dataiker, Dataiku DSS Core Designer, Dataiku DSS ML Practitioner, Dataiku DSS Adv Designer, Registered Posts: 1,399 Dataiker
Hi,
Did you retrain the model after making this change? Did you import these project libs in both your training recipe and in the API endpoint?
Given the nature I believe it would best to contineu this in a support ticket.
Can you please create a support ticket and attach the exported zip of the API endpoint from the API deployer along with the job diagnostics from the model training? Please don't share these on the community as all posts are public.
Thanks -
ahhh yes you right. okey.
but now is already solve so you right the 2 solution works in project library to create it. my previous problem is create the py file. but already make it correctly. thx




