Sign up to take part
Registered users can ask their own questions, contribute to discussions, and be part of the Community!
Registered users can ask their own questions, contribute to discussions, and be part of the Community!
Hey,
I've been running into an issue where after creating a dataset which is stored in parquet, while using a pyspark recipe, the dataset is redected as csv, without a very different schema.
Here's the dataset before pressing redetect format:
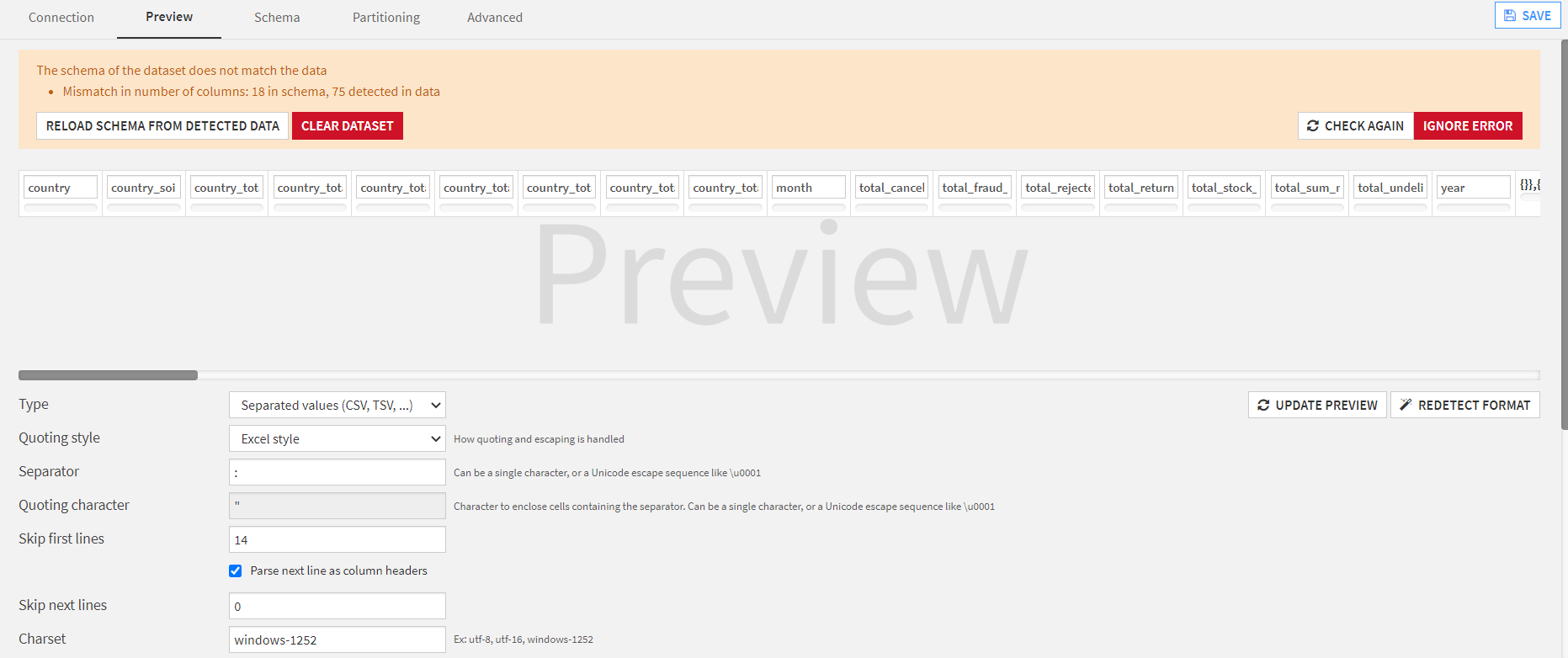
And after pressing redetect format, It goes from 18 to 75 columns:

And the new columns make no sense:

And to confirm the generated parquet files:

I've deleted and recreated the dataset multiple times, but I always get the same result.
I've also checked the pyspark recipe, but it generates the 18 supposed columns, not 75.
Any help would be appreciated, as I'm at a loss on what could be causing this issue.
Best regards,
Márcio Coelho
Operating system used: Windows
Hi @MarcioCoelho,
Thanks for writing in! Referencing your first snapshot, it appears that the dataset is originally detected as parquet. What happens if you don’t select “redetect format” and instead select “Check now”?
Alternatively, are you able to change the dataset to Parquet format using the “Type” drop-down menu and select update preview?
If the steps above do not work. Would you be able to share an example of the code you’re using to create the dataset?
Thanks again,
Jordan
Hey @JordanB thanks for your reply.
We got it working properly by using spark.dku.allow.native.parquet.reader.infer set to true, from https://doc.dataiku.com/dss/latest/connecting/formats/parquet.html.
We suspected that some of data had a weird format and as such was being wrongfully inferred.
Hi @MarcioCoelho could you please help us by telling where to add this property spark.dku.allow.native.parquet.reader.infer
Of course - Open the spark recipe, and on the top right corner select Advanced. Then add the parameter in the Override Configuration, like in the image below:
Thanks for the reponse @MarcioCoelho , in my pySpark query I read the data as dataIku dataset first and then do a spark.read.parquet . I am still not able to see the extra columns.
Any thoughts ?
I'm sorry, but I don't really understand what you mean. Could you post a screenshot of your flow with more details, for example, please?




{kind=link}
{kind=link}
{kind=link}