CloudStack環境でPySpark実行時に追加ライブラリ (JAR) を読み込ませたい

お世話になります。
AWS上にDataiku環境を構築しており、EKS上にクラスタも配置しております。この環境でNotebookおよびPySparkレシピにおいてPySparkを使ってEKSクラスタで処理を実行するようなコードを書こうとしています。
このコード内でSparkに追加ライブラリ (JARファイル) を読ませた状態でSparkSessionを起動したいのですが、クラスタに対してJARファイルをどうやって配置するべきなのか分からず困っております。
クラスタへJARファイルを配置する良い方法について、ご存じの方がおりましたらお知恵を拝借できますでしょうか。よろしくお願いいたします。
Dataiku version used: 14.4.1
Answers
-
 Tsuyoshi Dataiker, PartnerAdmin, Dataiku DSS Core Designer, Dataiku DSS ML Practitioner, Dataiku DSS Adv Designer, Registered Posts: 440 Dataiker
Tsuyoshi Dataiker, PartnerAdmin, Dataiku DSS Core Designer, Dataiku DSS ML Practitioner, Dataiku DSS Adv Designer, Registered Posts: 440 DataikerCloud Stacksを試せる環境が私の手元にないため、確実な回答ではないのですが、以下画像の管理画面の設定でJARファイルのパスを登録することは可能と考えられます。
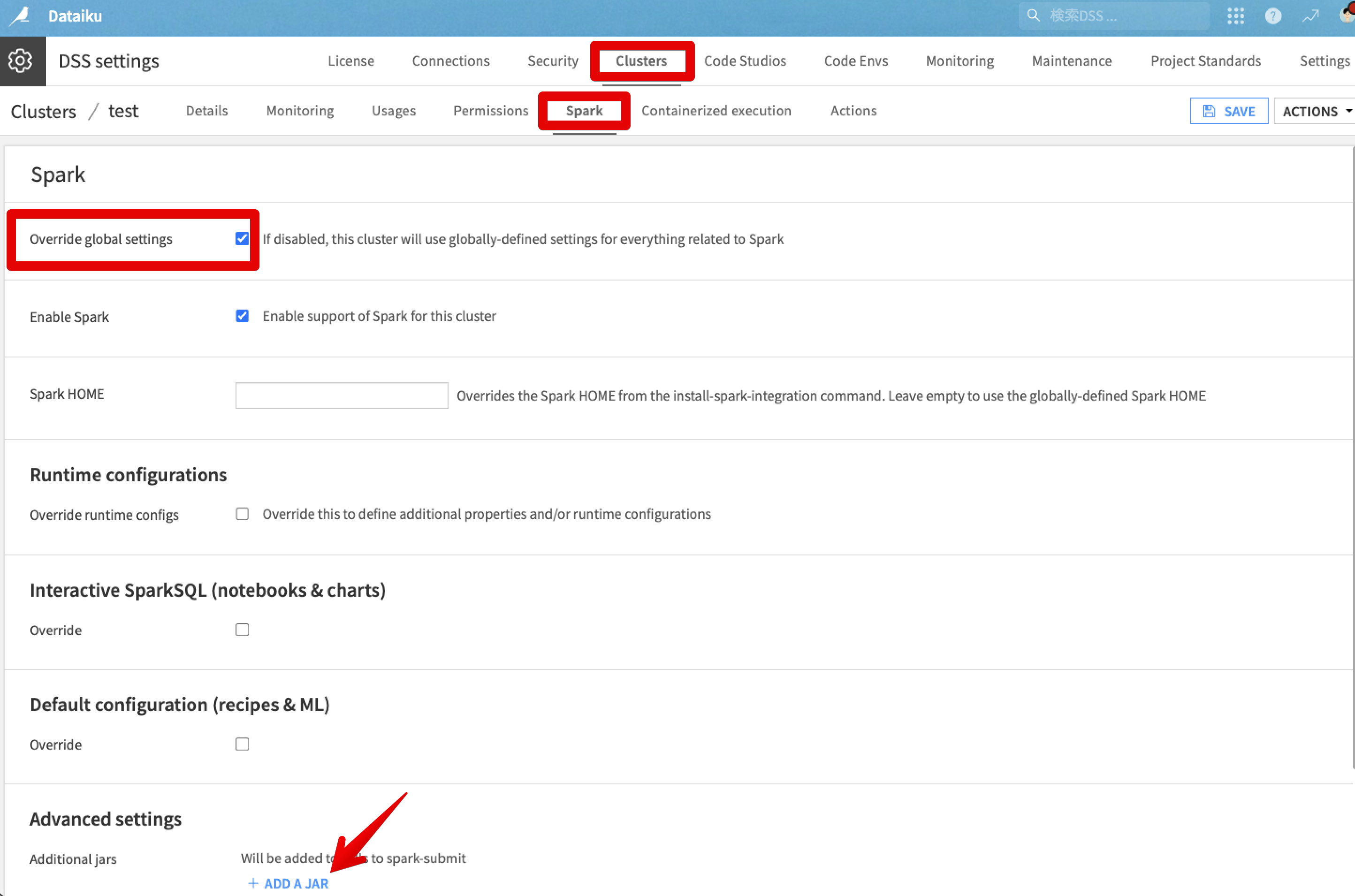
指定するJARファイルのパスですが、以下リンクに記載のように(こちらはJDBCドライバーの場合の例ですが)、対象サーバから参照可能なパスを指定していただければよいと考えられます。
上記、ご確認をいただけますと幸いです。もしご不明な点などございましたら、ご連絡ください。
ーーーーー
また、日本語でご質問をいただく場合には、こちらのグローバル掲示板でも英語で回答をもらえる可能性はありますが、以下の日本語用Q&Aコミュニティにご投稿をいただきますと、日本のメンバーに発見される可能性がより高まります。https://community.dataiku.com/categories/japan-user-group-(data-haiker)
今回、私はたまたま、こちらの投稿に気づいたのですが、今後は上記のリンクもご活用いただけますと幸いです!
