Default project key is not specified (no DKU_CURRENT_PROJECT_KEY in env)

I'm creating a python function endpoint with this script:
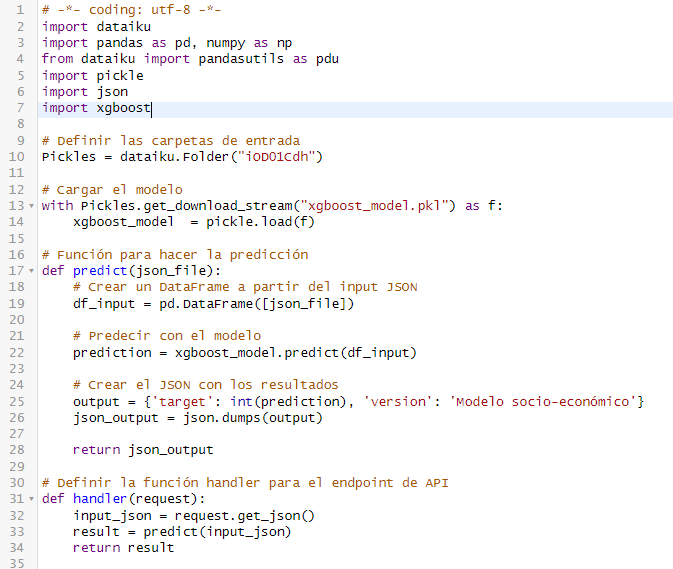
And I don't know how to deal with this error:
Dev server deployment FAILED
Failed to initiate function server : <class 'Exception'> : Default project key is not specified (no DKU_CURRENT_PROJECT_KEY in env)
Answers
-
 Turribeach Dataiku DSS Core Designer, Neuron, Dataiku DSS Adv Designer, Registered, Neuron 2023, Circle Member Posts: 2,663 Neuron
Turribeach Dataiku DSS Core Designer, Neuron, Dataiku DSS Adv Designer, Registered, Neuron 2023, Circle Member Posts: 2,663 NeuronHi, when posting code always use the code block (the </> icon in the toolbar) so your code snippet can easily be copied/pasted.
The API node doesn't have a project context. In fact the API node doesn't even have access to the project data so you will first need to establish a full Python API connection. I am guessing you are only testing in the Designer Node which comes with the API Note embedded into it which is why you haven't seen the URL error you should see with the above code. This URL should point to either a Designer or Automation node. And the API Key should be valid on those instances (see sample code below).
While you can fetch a model from a Managed Folder in a Designer or Automation node from an API service deployed in the API node you should consider if this is pattern you want to go for. API services can be deployed on High Availability mode in Kubernetes. But if your API service has to fetch a model from a Designer or Automation node you will have a single point of failure since neither the Designer Node nor Automation Node work in HA mode. This obviously means your API service will depend on the Designer Node / Automation Node being up to be able to predict data.
Then the other issue you got is that you are using the Internal DSS client. In general outside DSS you should be using the external API client (import dataikuapi) rather than the internal, unless there is something you want to do which is only available in the internal client.
import dataikuapi client = dataikuapi.DSSClient("https://dss.example/", "YOURAPIKEY") project = client.get_project("project_key") folder = project.get_managed_folder("my_folder_id")https://developer.dataiku.com/12/getting-started/dataiku-python-apis/index.html
-
Hello all,
i am still looking for a solution to my problem. I have the following Jupyter Notebook:
import dataiku
import pickle
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
import dataikuapi
def load_data(folder_name="Recommender"):
managed_folder = dataiku.Folder(folder_name)
with managed_folder.get_download_stream("cosine_similarity.pkl") as stream:
cosine_sim = pickle.load(stream)
with managed_folder.get_download_stream("tfidf_vectorizer.pkl") as stream:
vectorizer = pickle.load(stream)
with managed_folder.get_download_stream("tfidf_matrix.pkl") as stream:
X_tfidf = pickle.load(stream)
sachnummer = dataiku.Dataset("LTM_prep")
df = sachnummer.get_dataframe()
df.drop(['lieferant_name', 'lieferant_ort', 'LIEFERANT_NAME_ORT', 'LT_GEBINDE_NUMMER', 'MDI'], axis=1, inplace=True)
return cosine_sim, vectorizer, X_tfidf, df
def recommend_filtered1(input_bennenung, vectorizer, X_tfidf, df, top_n=10):
try:
if not input_bennenung:
return {"error": "Die Eingabe-Benennung darf nicht leer sein."}
input_bennenung = input_bennenung.upper()
input_vector = vectorizer.transform([input_bennenung])
similarities = cosine_similarity(input_vector, X_tfidf).flatten()
top_indices = similarities.argsort()[-top_n:][::-1]
recommendations = [
{"test": df.iloc[idx]['test'],
"test2": df.iloc[idx]['test2'],
"SIMILARITY_SCORE": round(similarities[idx], 2)}
for idx in top_indices if similarities[idx] > 0
]
return recommendations if recommendations else {"message": "Keine ähnlichen Benennungen gefunden."}
except Exception as e:
return {"error": f"Fehler: {str(e)}"}
def recommend_from_input(input_bennenung):
folder_name = "Recommender"
if not input_bennenung:
return {"error": "Fehlender Parameter 'input_bennenung'"}
try:
# Lade alle benötigten Objekte
cosine_sim, vectorizer, X_tfidf, df = load_data(folder_name)
# Empfehlung berechnen
return recommend_filtered1(input_bennenung, vectorizer, X_tfidf, df)
except Exception as e:
return {"error": f"Fehler beim Laden der Daten oder der Empfehlung: {str(e)}"}and want to call the method
recommend_from_inputfrom it. I am in the API Designer. I have a managed folder called "Recommender," which I can also see in the Flow. The structure im Folder is
Unter Folder Settings i see type is Amazon S3 and i have a setted connection and see also the path in bucket. So when i call def recommend_from_input(input_bennenung): return input_bennenung in the api designer code section with the test query
{
"input_bennenung": "Stern"
}there are no errors and i get "Stern back". So now i just pasted my notebook code in the api designer code Section and when i run it there is a error:
Result:
{"error":"Fehler beim Laden der Daten oder der Empfehlung: Default project key is not specified (no DKU_CURRENT_PROJECT_KEY in env)"}
In the logs are no errors only info and debug.
I would appreciate any help. I have already read the documentation on Exposing Python Functions, but I still don't know where my mistake is.
