Dataiku to Greenplum: Performance Lag on Large Data Loads & Batch Read Control

Hello,
During a Proof of Concept (PoC), we're experiencing performance degradation when loading 20 million rows of data with 500 columns into GPDB (Greenplum Database).
We've observed in the Dataiku logs that it continuously reads data in batches of 2000 rows. We're looking for a setting to adjust this batch size.
We've already tried setting the 'Fetch Size' in the connection settings and modifying relevant properties in the JDBC Connection URL, but these changes did not affect the behavior.
In this scenario, we would greatly appreciate any suggestions on how to improve the Read/Write performance for large datasets from the database.
Thank you in advance for your help!
Operating system used: RHEL
Best Answer
-
 Alexandru Dataiker, Dataiku DSS Core Designer, Dataiku DSS ML Practitioner, Dataiku DSS Adv Designer, Registered Posts: 1,399 Dataiker
Alexandru Dataiker, Dataiku DSS Core Designer, Dataiku DSS ML Practitioner, Dataiku DSS Adv Designer, Registered Posts: 1,399 DataikerHi,
With Greeplum, in the current DSS version, we support an in-database engine :
https://doc.dataiku.com/dss/latest/connecting/sql/greenplum.html
If you are running a Visual recipe like Prepare, it should be able to leverage the in-database engine. Given that you are using a compatible processor or all processors are configured to be SQL compatible and both input and output datasets in Greenplum, this should avoid having to stream the data in batches.
Did you change the fetch size at the dataset or connection level?
Note that you may not see a huge difference with different fetch sizes if you are using the streaming engine.
It would be best to perform as much of the flow in-database, and if needed, use a sync recipe to change the storage type. If the input dataset is larger and this data can be partitioned, you may want to consider using SQL Partitions. This will reduce the amount of data you need to read and allow for parallelization by running multiple concurrent partitions.
https://doc.dataiku.com/dss/latest/partitions/sql_datasets.html
Kind Regards
Answers
-
Alexandru Dataiker, Dataiku DSS Core Designer, Dataiku DSS ML Practitioner, Dataiku DSS Adv Designer, Registered Posts: 1,399 Dataiker
Hi @Sangcheul ,
Coud please share open a support ticket and share a job diagnosics so we can investigate futher:
Kind Regards,
-
 Turribeach Dataiku DSS Core Designer, Neuron, Dataiku DSS Adv Designer, Registered, Neuron 2023, Circle Member Posts: 2,718 Neuron
Turribeach Dataiku DSS Core Designer, Neuron, Dataiku DSS Adv Designer, Registered, Neuron 2023, Circle Member Posts: 2,718 NeuronIt sounds like your recipe it’s loading all data into DSS memory. This can happen for many reasons but it’s generally undesired for large datasets. What type of recipe are you using and can you paste a screenshot of the recipe in the flow showing inputs and outputs?
-
@Alexandru , @Turribeach
My apologies for the delayed response.My current work environment is subject to national industrial security policies and internet access is restricted. This makes it impossible to export any data for a more detailed analysis.
Regarding the data read from GPDB, we used a Prepare recipe. In this recipe, we performed several transformations, including date conversion, creating new columns with formulas, replacing missing values, and deleting specific columns.
-
Hi,
Thanks for your practical help!
I'll definitely be taking your last piece of advice and working with that. -
Turribeach Dataiku DSS Core Designer, Neuron, Dataiku DSS Adv Designer, Registered, Neuron 2023, Circle Member Posts: 2,718 Neuron
If you are using a Prepare recipe with inputs and outputs in a SQL database you will see the little SQL icons in red and green in each of the prepare steps. These icons indicate whether the step can be pushed down to the SQL database or not. A single red step will make the whole recipe to run in DSS and stream/batch the data so you need to be careful.
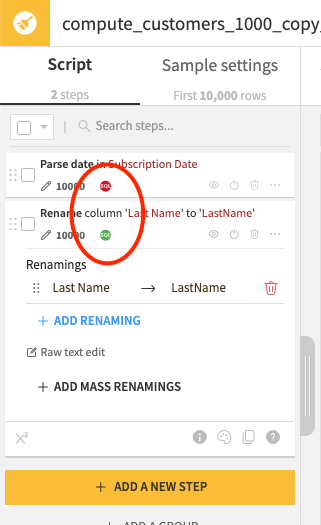
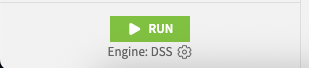
At the bottom left of the recipe screen you will see the engine that DSS will use. This can be DSS (slow/in memory/data streamed):
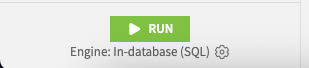
Or In-Database (SQL) which should be your aim:
You can enable and disable the recipe steps to test to see how the engine changes. Here is the documentation of which processors are supported in SQL:
A lot of the times the prepare processors are not translated into SQL not because they aren't supported by the SQL database but because Dataiku did not write the logic for that. In that case your only option is to either do these steps on a SQL recipe or take the performance penalty. You can also try to move these transformations to a later part of your flow where you might have less data to process which might reduce the performance penalty.


