Sign up to take part
Registered users can ask their own questions, contribute to discussions, and be part of the Community!
Registered users can ask their own questions, contribute to discussions, and be part of the Community!
Problem Statement:
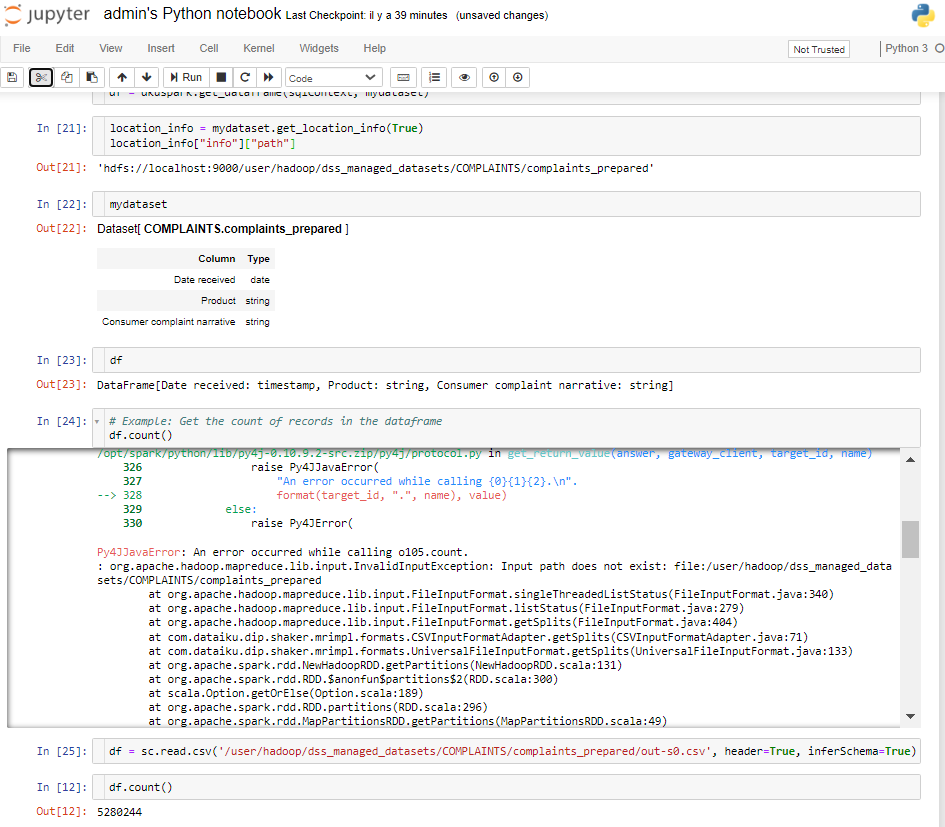
When attempting to read a Dataiku dataset into a Spark DataFrame using the Dataiku Python API (`dataiku.Dataset` and `dkuspark.get_dataframe`), an error occurs indicating that the input path does not exist. However, when directly reading the CSV file from HDFS using Spark's `read.csv` method, the operation succeeds without errors.
Environment:
Dataiku version: 11.3.2
Spark version: 3.2.0
Hadoop version: 3.3.5
Python version 3.7.17
Operating system: Ubuntu
Steps to Reproduce:
1. Create a SparkSession with HDFS configuration using the following code:
```python
import dataiku
import dataiku.spark as dkuspark
import pyspark
from pyspark.sql import SQLContext, SparkSession
sc = SparkSession.builder.config("spark.hadoop.fs.defaultFS", "hdfs://localhost:9000").getOrCreate()
sqlContext = SQLContext(sc)
```
2. Attempt to read a Dataiku dataset into a Spark DataFrame using the Dataiku Python API:
```python
mydataset = dataiku.Dataset("complaints_prepared")
df = dkuspark.get_dataframe(sqlContext, mydataset)
df.count()
```
3. Observe the error message:
```
Py4JJavaError: An error occurred while calling o123.count.
: org.apache.hadoop.mapreduce.lib.input.InvalidInputException: Input path does not exist: file:/user/hadoop/dss_managed_datasets/COMPLAINTS/complaints_prepared
...
```
Observations:
- The error message indicates that Spark is trying to interpret the path as a local file system path (`file:/user/hadoop/dss_managed_datasets/COMPLAINTS/complaints_prepared`) instead of an HDFS path.
- However, directly reading the CSV file from HDFS using Spark's `read.csv` method works without errors.
Expected Behavior:
- The Dataiku Python API should correctly interpret the path as an HDFS path and successfully read the dataset into a Spark DataFrame without errors.
Additional Information:
- Both Spark and Hadoop are enabled and configured properly, as evidenced by the successful operation when directly reading from HDFS using Spark's native methods.
Request for Assistance:
- Kindly provide insights into why the Dataiku Python API might be interpreting the path incorrectly or suggest any troubleshooting steps to resolve the issue.
Operating system used: Ubuntu

{kind=link}
{kind=link}
{kind=link}