Sign up to take part
Registered users can ask their own questions, contribute to discussions, and be part of the Community!
Registered users can ask their own questions, contribute to discussions, and be part of the Community!
Hi,
I've uploaded a parquet file from AWS S3 and the columns are not correctly displayed.
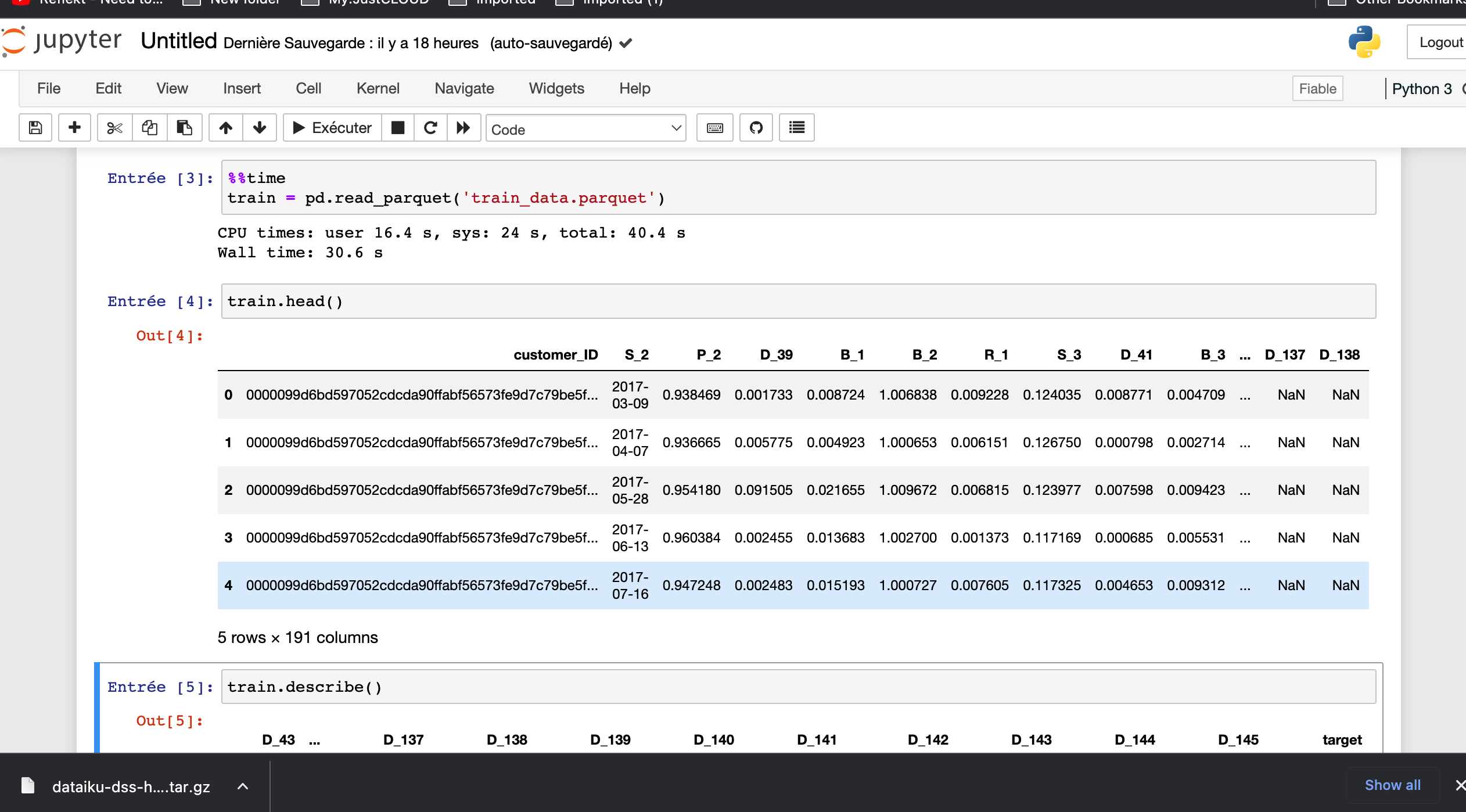
I've uploaded same parquet file locally on my computer and I share 2 screenshots, one correctly uploaded with the shape of the dataframe, variables content (Output Parquet Local Computer) and the second screenshot with the preview from Dataiku (Output Parquet from AWS S3)
The "conversion" from parquet into CSV seems not working.
Operating system used: Mac OS
Hi,
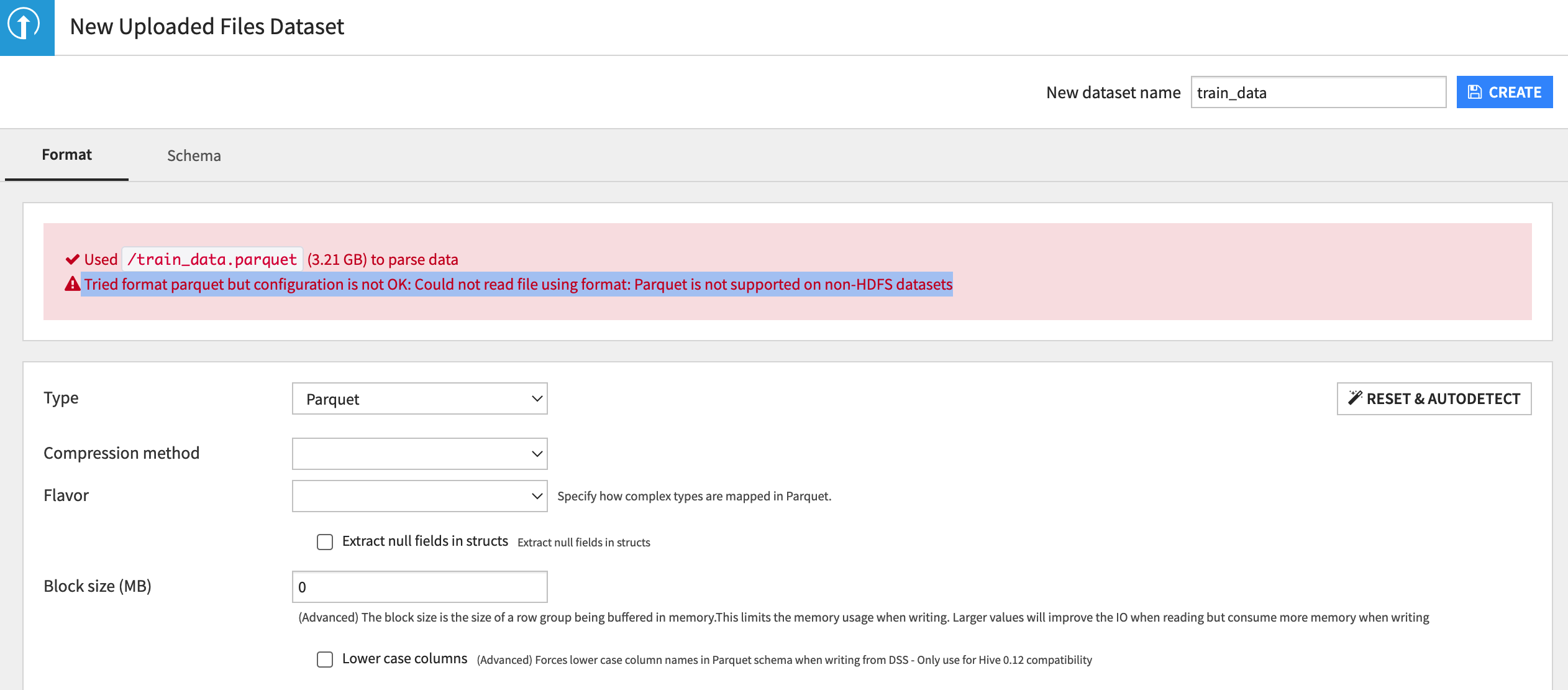
It seems Dataiku can't read files on non HDFS datasets.
"Tried format parquet but configuration is not OK: Could not read file using format: Parquet is not supported on non-HDFS datasets"
"Dommage...."
Hi,
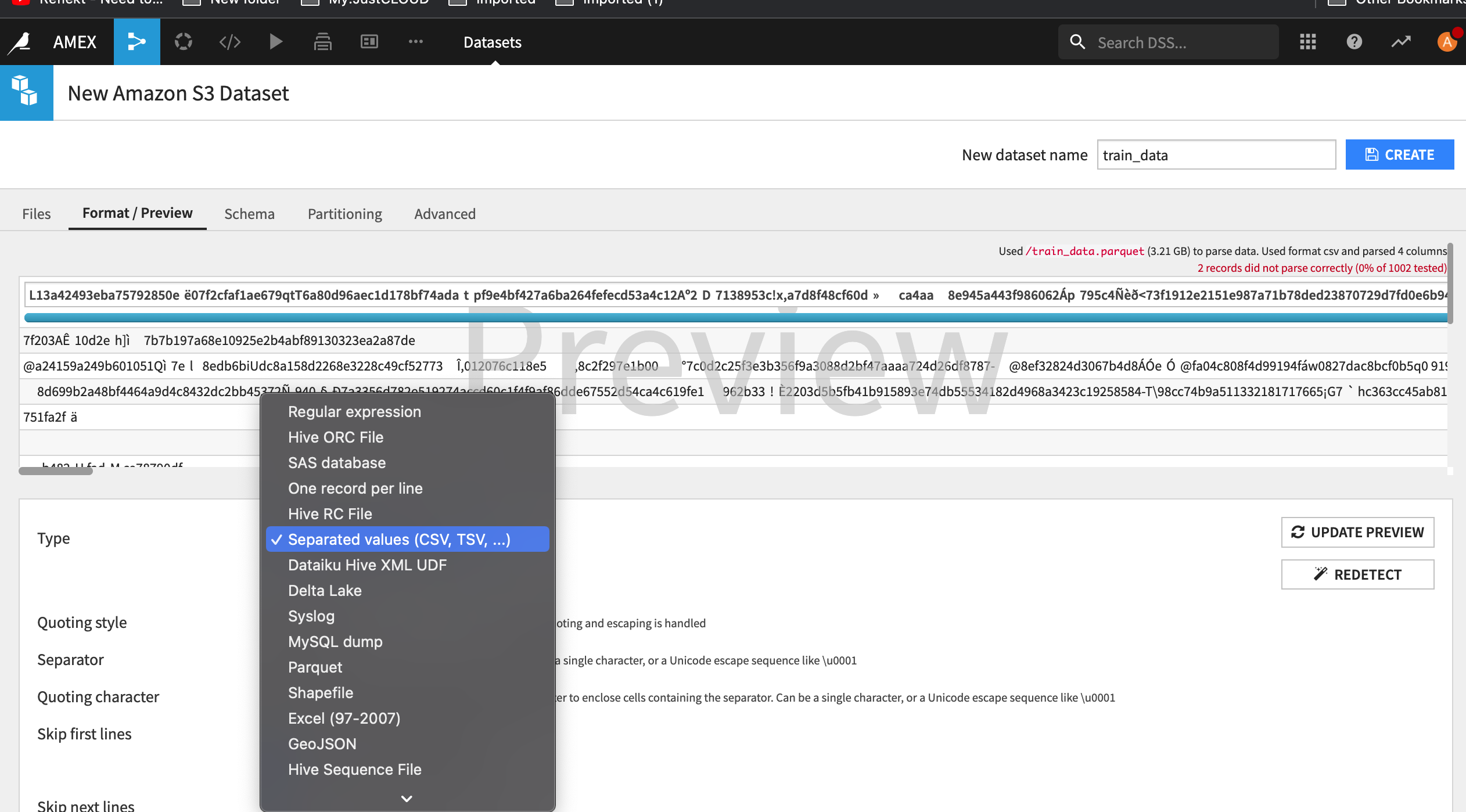
you need to change the format to Parquet in the Format / Preview tab of your screenshot. DSS wasn't able to correctly detect that the data is parquet.
Note that parquet has a lot of ties to Hadoop libraries, and in particular it needs to work on folders rather than on individual files. Which means that you should have the tain.parquet file in some folder on S3 and select the folder for the dataset path.
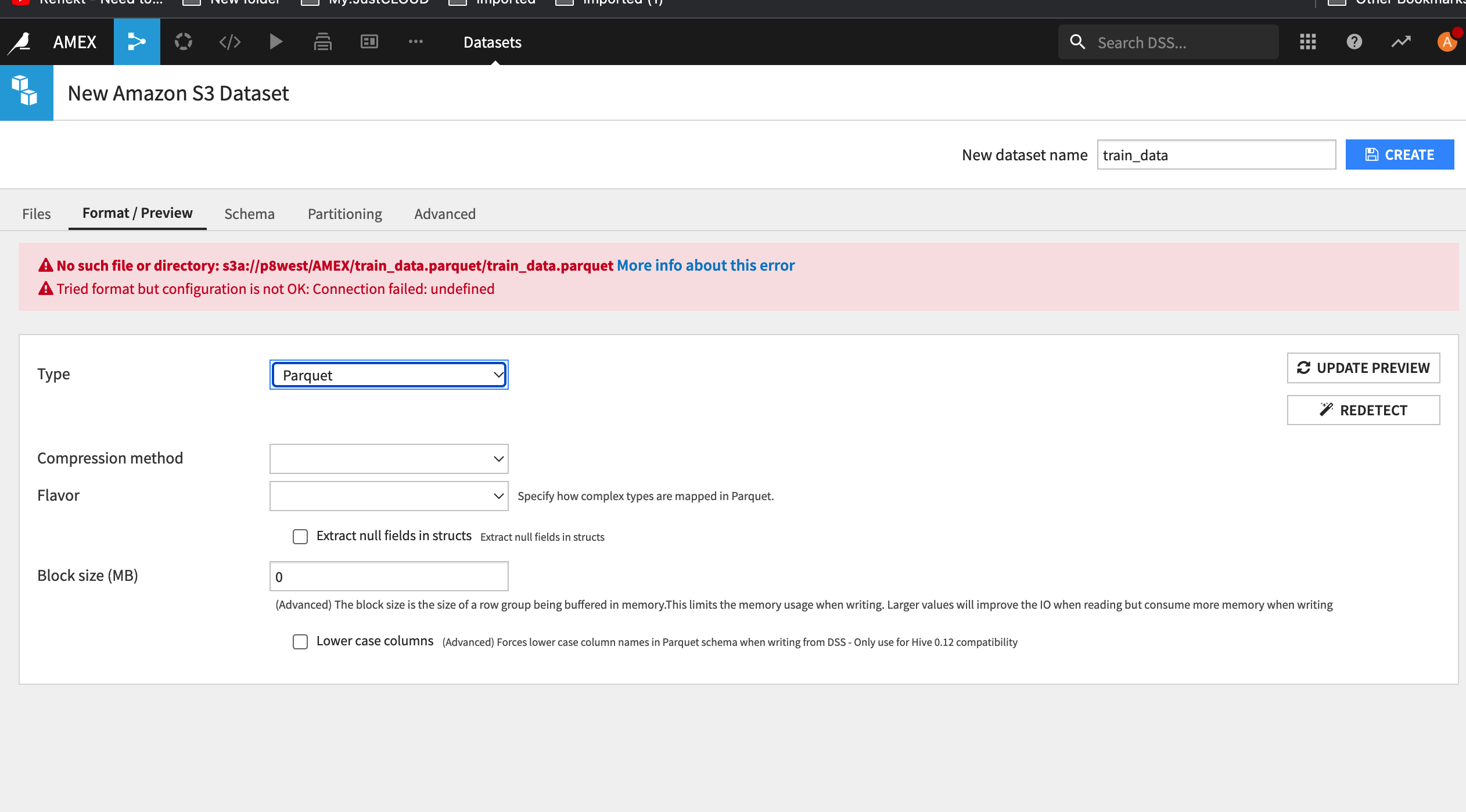
That's what I did, I change the format but I get another error
No such file or directory: s3a://p8west/AMEX/train_data.parquet/train_data.parquet
Tried format but configuration is not OK: Connection failed: undefined
So I've tested creating a folder in S3 as described in error message s3a://p8west/AMEX/train_data.parquet/train_data.parquet
but then I get
No such file or directory: s3a://p8west/AMEX/train_data.parquet/train_data.parquet/train_data.parquet
If I select a folder instead of a file, the process never ends
if the full path to the parquet file is s3a://p8west/AMEX/train_data.parquet/train_data.parquet , then the dataset path should be s3a://p8west/AMEX/train_data.parquet/ . The name of the folder (ending in .parquet) may be misleading.
That's what I did.
If I just enter the path, it nevers finnish loading the file
never loading a parquet file stored on S3 is not really expected. You'd need to generate a diagnostic of the instance in Administration > Maintenance > Diagnostic tool and create a support ticket with that on support.dataiku.com
as said before, Parquet has strong ties to Hadoop libraries, and only by using python libs that reimplement a good chunk of parquet can you avoid that fact. You need to put the parquet files on a HDFS connection, or HDFS-able one like S3/Azure blob/GCS (in which case the HDFS interface field of the DSS connection needs to be set)

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}