Upsert of daily data in Dataiku DSS
I work on data fed daily and I try to find a way in Dataiku to do upsert: do at the same time update records and insert new records, what are the different ways to do this please?
Answers
-
 Manuel Alpha Tester, Dataiker Alumni, Dataiku DSS Core Designer, Dataiku DSS ML Practitioner, Dataiku DSS Core Concepts, Dataiku DSS Adv Designer, Registered Posts: 193 ✭✭✭✭✭✭✭
Manuel Alpha Tester, Dataiker Alumni, Dataiku DSS Core Designer, Dataiku DSS ML Practitioner, Dataiku DSS Core Concepts, Dataiku DSS Adv Designer, Registered Posts: 193 ✭✭✭✭✭✭✭Hi,
I recommend that you have a look at the partitioning functionality, which allows you to process your dataset in specific chunks, for example your "daily feed":
- Introduction video,
//play.vidyard.com/w7ozrFT3REzedHvv6hKriJ.html?
- Academy course, https://academy.dataiku.com/advanced-partitioning
I hope this helps.
-
 Turribeach Dataiku DSS Core Designer, Neuron, Dataiku DSS Adv Designer, Registered, Neuron 2023, Circle Member Posts: 2,682 Neuron
Turribeach Dataiku DSS Core Designer, Neuron, Dataiku DSS Adv Designer, Registered, Neuron 2023, Circle Member Posts: 2,682 NeuronThere is a new Upsert recipe plugin available in 13.5.0:

However the documentation seems missing:
-
 tgb417 Dataiku DSS Core Designer, Dataiku DSS & SQL, Dataiku DSS ML Practitioner, Dataiku DSS Core Concepts, Neuron 2020, Neuron, Registered, Dataiku Frontrunner Awards 2021 Finalist, Neuron 2021, Neuron 2022, Frontrunner 2022 Finalist, Frontrunner 2022 Winner, Dataiku Frontrunner Awards 2021 Participant, Frontrunner 2022 Participant, Neuron 2023 Posts: 1,644 Neuron
tgb417 Dataiku DSS Core Designer, Dataiku DSS & SQL, Dataiku DSS ML Practitioner, Dataiku DSS Core Concepts, Neuron 2020, Neuron, Registered, Dataiku Frontrunner Awards 2021 Finalist, Neuron 2021, Neuron 2022, Frontrunner 2022 Finalist, Frontrunner 2022 Winner, Dataiku Frontrunner Awards 2021 Participant, Frontrunner 2022 Participant, Neuron 2023 Posts: 1,644 Neuron@Turribeach , do you know if the Upsert recipie works on partitioned data? And do you know a way to do deletes on rows of data within a prartition rather than re-computing the entire partition or worse the entire dataset?
-
Turribeach Dataiku DSS Core Designer, Neuron, Dataiku DSS Adv Designer, Registered, Neuron 2023, Circle Member Posts: 2,682 Neuron
No idea sorry.
-
 Alexandru Dataiker, Dataiku DSS Core Designer, Dataiku DSS ML Practitioner, Dataiku DSS Adv Designer, Registered Posts: 1,399 Dataiker
Alexandru Dataiker, Dataiku DSS Core Designer, Dataiku DSS ML Practitioner, Dataiku DSS Adv Designer, Registered Posts: 1,399 DataikerI see no restriction on using partitioned input/output for the upsert recipe.
I tested on DSS 14.2.1 / 1.0.2deed it upserts based on the selected mode and partitioned:
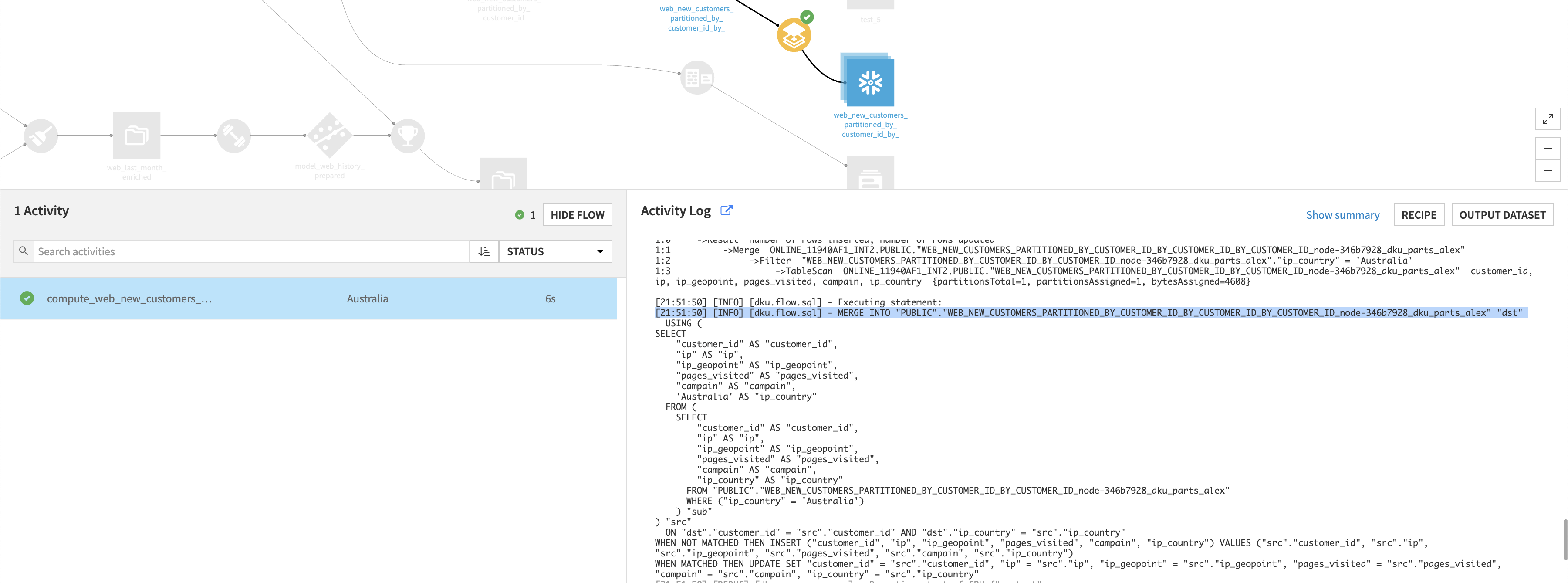
Thanks
-
tgb417 Dataiku DSS Core Designer, Dataiku DSS & SQL, Dataiku DSS ML Practitioner, Dataiku DSS Core Concepts, Neuron 2020, Neuron, Registered, Dataiku Frontrunner Awards 2021 Finalist, Neuron 2021, Neuron 2022, Frontrunner 2022 Finalist, Frontrunner 2022 Winner, Dataiku Frontrunner Awards 2021 Participant, Frontrunner 2022 Participant, Neuron 2023 Posts: 1,644 Neuron
Thanks for the comment. That is super interesting.
Now I need to get my brain around how to use this in my use case.
I have a REST API provided by a vendor that is super slow, taking a good part of a second to produce a new record. On typical days I only have 500 new and updated records of 700,000+ records in the data set. In some day I might have 40,000 to 50,000 records updated in the source system. These records are not stored in a transactional way. I have to look at update dates and find either new records or updated records. And then I have to process that data through 4 projects to normalize the data and do standard cleanup, before putting the data into a "golden data set" that other projects use to do the work they need to do. The goal is to keep the dataset up to date within a few hours.
I have a process that:
- Daily pulls all of the summary records for the dataset (this can be done in 10 min or so.)
- Look for summary data that has been updated since the last time I pulled data from the rest API. That can be done with the same summary REST API call.
- Then I determine which Summary records that I have do not have up to date detail data.
- Then I get 0 to 7,500 detail records as needed from the API.
- Then Join the Detail record components to the summary record components (Dropping any records for which I do not have summary records details. (this deals with record deletes.)
- Then stack all of the existing details records both new and old.
- Then pick out the most recent record for which I have Summary and Detail records. (This does the update and insert actions.
This optimizes that I'm not making complete detail record pulls. I'm only pull detailed records when there are either new or updated details.
I only pull all of the summary data once a day. To find out what records are deleated.
Then I have to process the records by:
- Normalizing the data into a relational database configuration this is done in it's own project
- Doing typical data cleanup this is done in it's own project
- Each of the projects that does a business process pull a subset from the cleaned up data.
This is well and good. However, it is getting very slow and only getting slower each day. For example in the typical datacleanup project I'm processing 30,000,000 records for a few 10s of thousands of records a day. Almost all of which did not change in the past hour.
Question:
- How might we use any or all of the following to make this more efficient maintaince of a slowly changing golden data set that is not deliverd with transactional changes pulled through the API butare pulled through a slow REST API.
- The current older features include in this process.
- Stack data
- Window data and drop all but the most recent data in each window (record)
- Senarios
- SQL queries to pull state from datasets that are later in the dataflow so the steps earlier in the process know what data they would attempt to pull.
- Some of the new features might include
- Dataset partioning
- The Upsert Plugin
- The current older features include in this process.
All thought are welcome. Thanks.
-
Alexandru Dataiker, Dataiku DSS Core Designer, Dataiku DSS ML Practitioner, Dataiku DSS Adv Designer, Registered Posts: 1,399 Dataiker
Hi,
I think you are spot on about possible optimization paths, especially around :
"For example, in the typical data cleanup project, I'm processing 30,000,000 records for a few 10s of thousands of records a day"
This is exactly where partitions are useful, if you have SQL datasets partitioned by a column like "last_updated_day"
You can run your data clean-up targeting only that partition and on those records, using a scenario with the PREVIOUS_DAY or CURRENT_DAY, which would reduce the time it takes to run that flow.
It should be noted that it would be beneficial to avoid re-dispatching for such large datasets, especially if they are already SQL datasets. So, if you combine UPSERT and PARTITIONED, this should be ideal for reducing the number of records you have.
In your flow, you create a new SQL dataset that points to the same table (but with a different partition).
UPSERT doesn't handle DELETED records; you will need to use LEFT ANTI JOIN, but you can probably handle them separately in Spark SQL/SQL recipe.
If you need further guidance, please reach out to us via Chat support so we can assist.
Thanks -
tgb417 Dataiku DSS Core Designer, Dataiku DSS & SQL, Dataiku DSS ML Practitioner, Dataiku DSS Core Concepts, Neuron 2020, Neuron, Registered, Dataiku Frontrunner Awards 2021 Finalist, Neuron 2021, Neuron 2022, Frontrunner 2022 Finalist, Frontrunner 2022 Winner, Dataiku Frontrunner Awards 2021 Participant, Frontrunner 2022 Participant, Neuron 2023 Posts: 1,644 Neuron
Thanks.
I actually think that this topic may be of general intrest. So, I'm going to continue here a bit before we take this over to a more private support chat.
How are you imagining the use of the Left Anti Join to handle the delete case. And what databases support this type of join it appears that SPARK might support a Left Anti Join. The Anti Join clearly identifies the deleted records. If you can get to the entire dataset. The question is how to use that knowledge to cleanup and expunge the records from the dataset. So that the right dataset will eventually not contain the deleted records.
How are you imagining that we would clean up old records in partitions that have been superseeded in a year I might have 3.5 million records that are older versions of a record and are no longer valid not in the current day partition. Maybe that is where the UPSERT comes into play. However, those records might be in any partition across the dataset. Is there a way to populate and work on a dataset by partition some times as well as the entire dataset some times? Or is this going to be a case where one would have to itterate through all of the partitions. At least you might know which partition to look at if you used the creation date to partition.
Are you suggesting that I
1. Build the dataset partitioned by create date.2. Then when New Data comes in for records use UPsert for the entire dataset
3. Once I know which records to delete with the Left Anti Join. How do I remove just those records from a partitioned dataset. Again they are going to be in partitions all over the dataset.
I think I need to think about this some more. I think I'm missing some understanding about working with partitioned datasets.


