The recipe execution is taking long time due to handling a large volume of data in dataiku

We are experiencing long execution times for a recipe in Dataiku due to handing large datasets, while we have implemented partitioning using a filter on a specific column, it still takes 1.5-2 hours to partitioning 30M records. Is there a more efficient way to handle and process this data quickly and effectively because we'll be using more recipe throughout the flow like join, prepare sync etc..
Operating system used: Windows 11
Answers
-
Hi Mohammed,
I hope that you are doing well. This will be better handled through a support ticket so we can get more informations regarding your use case and work with you on performance improvement. Could you please submit a support ticket (https://support.dataiku.com/support/tickets/new)?
We will be able to best assist you there.
Best,
Yasmine
-
 Turribeach Dataiku DSS Core Designer, Neuron, Dataiku DSS Adv Designer, Registered, Neuron 2023, Circle Member Posts: 2,677 Neuron
Turribeach Dataiku DSS Core Designer, Neuron, Dataiku DSS Adv Designer, Registered, Neuron 2023, Circle Member Posts: 2,677 NeuronWhat type of connection is your dataset using?
I will suggest you move away from partitioning data in Dataiku. Partitioning data in Dataiku does not improve performance like in other technologies, it merely avoids having to compute the whole dataset. This may reduce compute time but it introduces a whole set of limitations and issues when using partitions in Dataiku. If you only aim for using partitioning in Dataiku is performance you should move away from that and look at data technologies that can handle your datasets matching your performance requirements. A few samples are Databricks, BigQuery or Snowflake.
-
By using both boto3 to access S3 buckets and polars to read (scan) your data, you can process a huge size of data very quickly. As an example, I can't show you the data, but you can trust me :
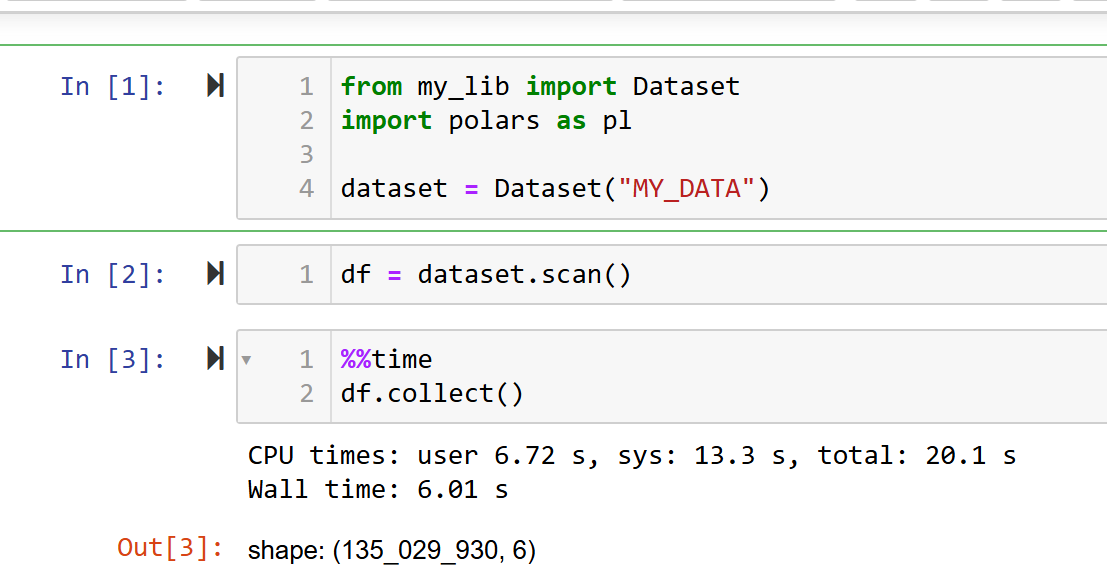
I defined on my_lib a sub-class of Dataset and added a method to scan data with polars directly from S3.
Here the data collected has 135M of rows and 6 columns, all this in 6.01s seconds.

