Sign up to take part
Registered users can ask their own questions, contribute to discussions, and be part of the Community!
Registered users can ask their own questions, contribute to discussions, and be part of the Community!
Hello everyone,
in Shapley computation using UDF we encouter memory issues or very long processing time.
Tryng to redefine the process with pySpark recipe we use the method "GBTClassificationModel.load" from the library "from pyspark.ml.classification import GBTClassificationModel" in custom code.
Unfortunately the load method takes too long (more than 4h) to upload the model.
Do you know how to speed up the process or work directly with the model without loading it?
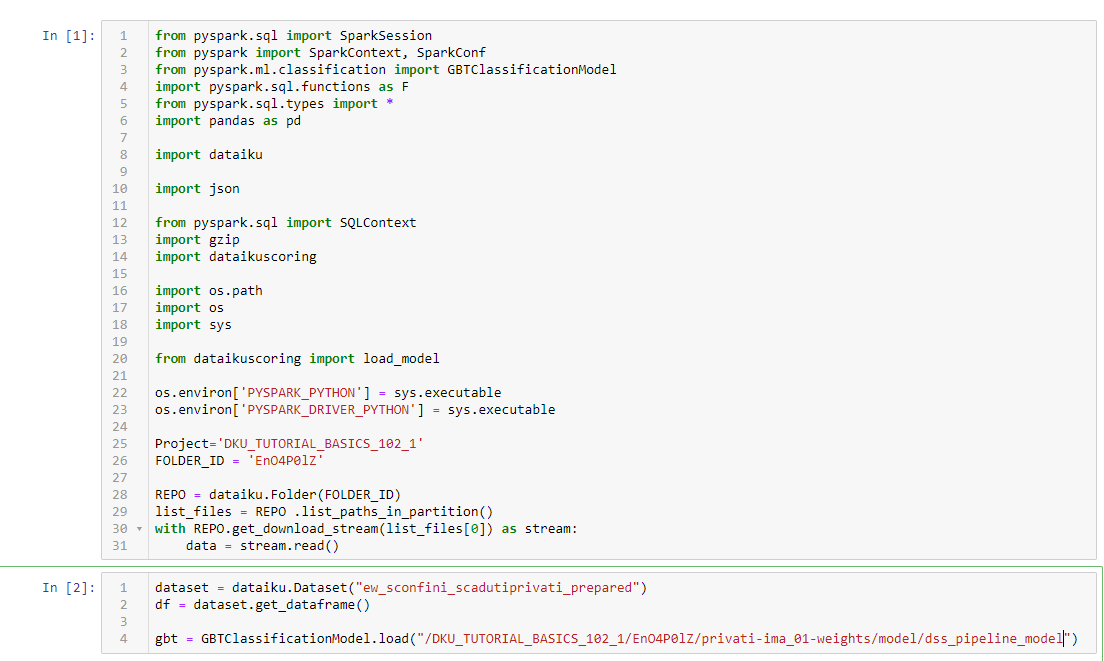
I leave attached the code snippet
Hi, can you please paste the code in a Code Block (look for the </> icon) so it can be copy/pasted? Thanks
from pyspark.sql import SparkSession
from pyspark import SparkContext, SparkConf
from pyspark.ml.classification import GBTClassificationModel
import pyspark.sql.functions as F
from pyspark.sql.types import *
import pandas as pd
import dataiku
import json
from pyspark.sql import SQLContext
import gzip
import dataikuscoring
import os.path
import os
import sys
from dataikuscoring import load_model
os.environ['PYSPARK_PYTHON'] = sys.executable
os.environ['PYSPARK_DRIVER_PYTHON'] = sys.executable
Project='DKU_TUTORIAL_BASICS_102_1'
FOLDER_ID = 'EnO4P0lZ'
REPO = dataiku.Folder(FOLDER_ID)
list_files = REPO .list_paths_in_partition()
with REPO.get_download_stream(list_files[0]) as stream:
data = stream.read()
dataset = dataiku.Dataset("ew_sconfini_scadutiprivati_prepared")
df = dataset.get_dataframe()
gbt = GBTClassificationModel.load("/DKU_TUTORIAL_BASICS_102_1/EnO4P0lZ/privati-ima_01-weights/model/dss_pipeline_model")
{kind=link}