Sign up to take part
Registered users can ask their own questions, contribute to discussions, and be part of the Community!
Registered users can ask their own questions, contribute to discussions, and be part of the Community!
While creating a scenario for partitioning a dataset on RunID, I'm getting a KeyError: 'RunID'. How to rectify it.
Thanks,
Parul.
Hi,
Could provide some more details on your scenario?
1) Are you using a custom python step?
2) Can you share the exact code you are trying to use and the results in the Key Error?
3) Is this, SQL, Filesystem dataset?
Thanks,
Hi Alex
Yes, I'm using a custom python script.
The scenario that I'm creating:
from dataiku.scenario import Scenario
import dataiku
scenario = Scenario()
partitions_dataset = dataiku.Dataset("dumpdata_raw")
partitions_list = list(partitions_dataset.get_dataframe()['RunID'].values)
# Building a dataset
scenario.build_dataset("All_raw_dumps", partitions=",".join(partitions_list), build_mode='NON_RECURSIVE_FORCED_BUILD',fail_fatal=False)
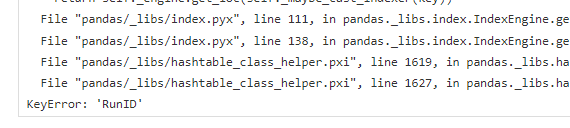
Attaching the error.
Thanks,
Parul.
Hi Parul, The key error is because the dataset dumpdata_raw doesn't contain a column RunID. If this is a filesystem dataset please note the partitioning column is removed when re-dispatching.
You can list all partitions with partitions_list = dataset.list_partitions()
scenario = Scenario() d
dataset = dataiku.Dataset("input_dataset_name")
scenario.build_dataset("All_raw_dumps", partitions=",".join(partitions_list), build_mode='NON_RECURSIVE_FORCED_BUILD',fail_fatal=False)
Let me know if that works for what you are trying to do.
Hi Alex,
Thanks for the RCA :), I've rectified my code to get the column: RunId in dataset dumpdata_raw.
Again created the scenario for reading the partitions, however, now I'm only able to get 1 partition (there are many more).
How to rectify it?
Thanks,
Parul.
Can you share the code you are using to read the partitions?
You will need to explicitly pass the partitions you want to read.
Here is an example :https://community.dataiku.com/t5/Using-Dataiku/Reading-partitions-one-at-a-time-from-Python/td-p/499...
Hi Alex,
What I was initially doing was saving the dump files of all the runs in a single non-partitioned dataset, and then using a python recipe to make them partitioned by RunID.
Now, I tried to do it in a different manner, I imported dump files directly into the partitioned dataset. However, while running the scenario, it failed with this error: Exception: No column in schema of Project.my dataset. Have you set up the schema for this dataset?
Thanks,
Parul.

{kind=link}