Sign up to take part
Registered users can ask their own questions, contribute to discussions, and be part of the Community!
Registered users can ask their own questions, contribute to discussions, and be part of the Community!
Hello community,
I'm quite new to Dataiku. I have a huge disappointment when I see the predicted data after the modelling under visual analysis has auto detected data types and not the ones which I have explicitly changed, Does that mean model is trained on the data types auto detected and not as per the data types manually given ? Could you please clarify my doubt ?
@maryas ,
+1, I've had similar experiences. (Which frankly, I've not reported to date. Partially thinking that maybe I'm doing something wrong.)
I'm wondering how we can better share these type of scenarios with the support team. Have you shared a support ticket detailing the specific example you are seeing? I'm thinking that this might help all of us.
Thank you @maryas, @tgb417 , for sharing this.
I am pleased to report that the input types you have explicitly set, and the feature processing options you may have selected, are adhered to when training & scoring your model however your observation is correct, it is possible that the "predicted data" displays different types, as some complex types (e.g. map) undergo transformation during processing.
As we are currently investigating how we can improve this, it would be great if you could share the data types which you noticed as not being preserved as expected.
Hello Krishna,
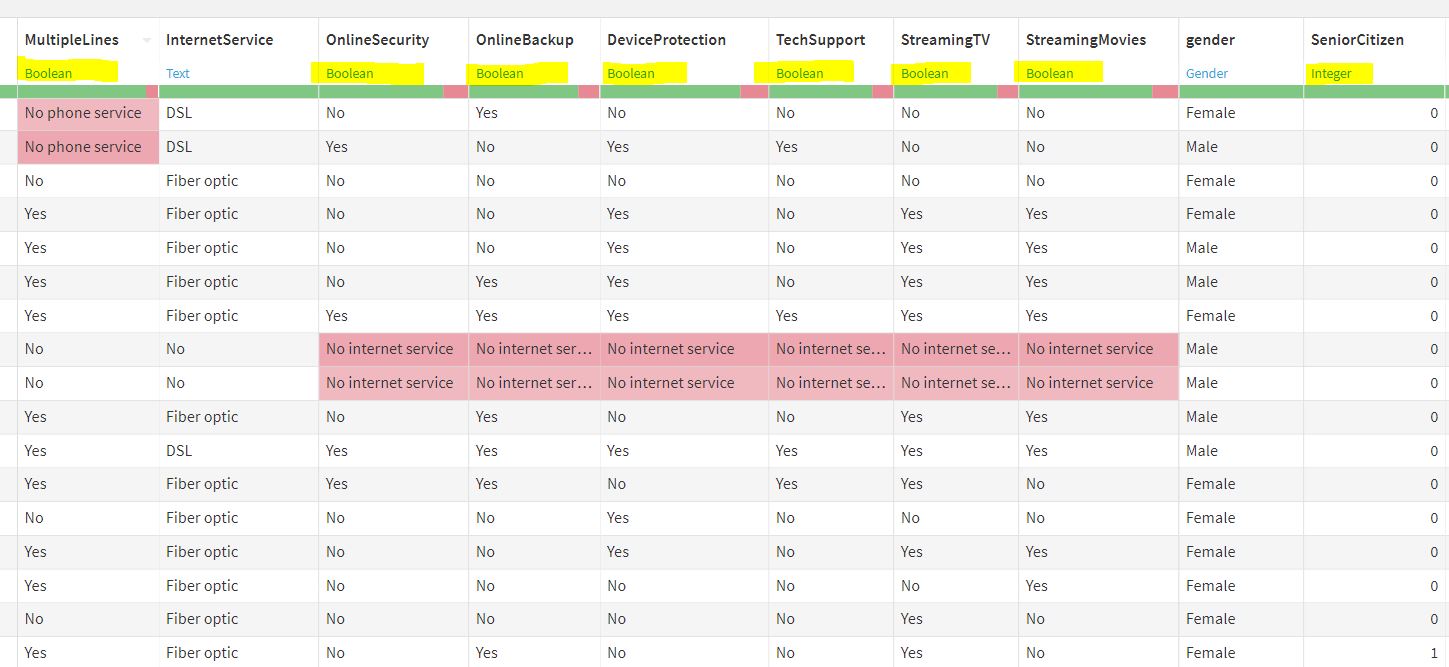
PFA 2 images 1) for the data having data types explicitly changed and 2) data types being auto-detected after prediction in the Labs. Mostly all of the Boolean values get auto-detected. But there were scenarios where data types were auto detected as integers though they had been explicitly changed to Booleans. But I have noticed this happens not only in the Lab but also in the Flow after scoring or evaluation recipe as well.
Regards !
Ah, this is a subtly different, but related issue, to what I suspected.
The difference you observe here is with the meanings, which is clearly not ideal, and something that we will look to address.
When you "Explore" the resulting dataset of a score recipe, can you confirm whether the object storage types remain consistent for you?
Krishna,
The same behaviour is observed for 'Explore' under Score recipe. ie. data types are auto-detected and not taking the data types forced by the user.
Regards !
@Krishna ,
It's been a while since I had this problem. I'm doing a cluster model in the middle of my flow as a feature engineering step. I ended up taking the cluster model down to just a few features. And in effect bypassing the main data set around the model flow, that is causing schema problems. And then re-joining the main data flow to the results of the model. See below for the flow I ended up with.
@maryas ,
I hope something like that might be a workaround for you. (Potentially not very space or compute-friendly.)
Thanks for the example Tom. That is indeed disappointing if the underlying storage types/schemas are being affected in this way. When you next observe this, please do share what you can around the column types/setup that has proven inconsistent through these pipeline stages.
@Krishna ,
To your point to @maryas , I don't remember if the reason that I ended up doing this was related to storage type or meaning. I have a sense that this might have been a breaking problem, as opposed to an inconvenience.
If I find myself down that whole again. I'll drop a support ticket, and try to reference this conversation as well. Sorry, I don't have more.


{kind=link}
{kind=link}