Sign up to take part
Registered users can ask their own questions, contribute to discussions, and be part of the Community!
Registered users can ask their own questions, contribute to discussions, and be part of the Community!
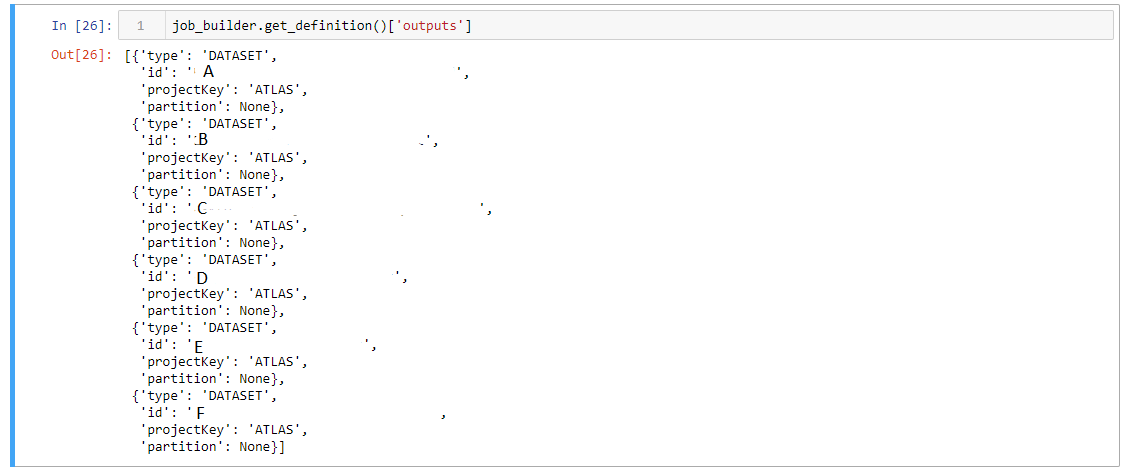
I have been using the dataiku API to make an algorithm and it involves executing multiple recipes. I am using the job_builder so that the recipes can be executed in "one job" (meaning that there will be only one row in the "Jobs" tab). Before running the job, I have collected all of the necessary outputs (datasets, managed folders, etc.) to be added to the job_builder using the method "with_output".
In the attached picture below (Screenshot 1-edit) is my current job_builder, with the recipes to be executed. Now I want the recipes to be executed one after the other according to the order that I have added to the job_builder (See Screenshot 1-edit). When I execute the job_builder with the method "start()", it does the job in one "job" (there is only one row in the "Jobs" tab), however, the recipes in the job are executed parallelly, which is not desired, because some recipes depend on other recipes. (In this case, the order that the recipes should be executed is : A, B, C, D, E, F. Meanwhile, with the method "start", the recipes are executed as following : E, C, D, B, F, A. This is random, as I tried running the code again and I got a different order.)
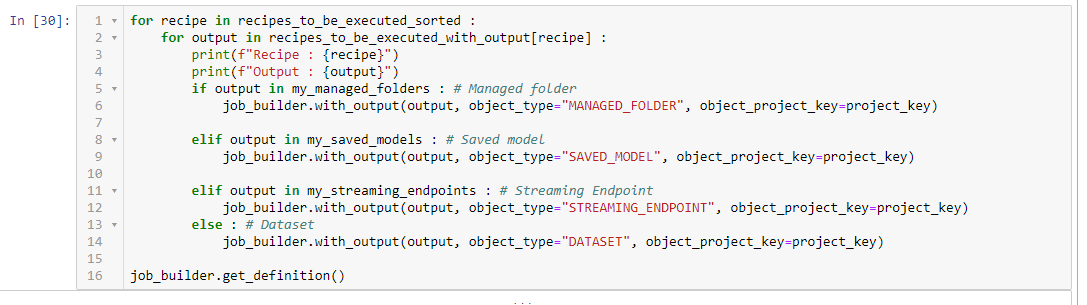
In "Screenshot 3" I have attached on how I added the output names to the job_builder by using for loops. Is there a way that I can execute the recipes one after the other? I tried to apply the "start" method in each loop, but it results in multiple rows in the "Job" tab, which I don't want, since the job might consist of a lot of recipes.
Thank you in advance!
Operating system used: Windows
Is there a way that I can execute the recipes one after the other?
Yes, use Scenarios not jobs. You should really stay away from using jobs for programmatic flow building. Jobs are meant only for development and adhoc building only. For scheduled/programmatic flow building Scenarios are the right tool. You can create Build Scenario steps in your Scenario and select the datasets you want to build in them or use the smart recursive logic, up to you. Each Scenario step will execute sequentially as part of the Scenario run. You can also build your Scenarios programmatically if you want. Or even have a Scenario be a Python script, so no GUI with scenario steps.
Thanks for the reply. I do realize that scenario is a solution, but I am not building scheduled flow. I created the algorithm just to execute some recipes that I want, but not all downstreams nor upstreams, and it is not possible to click on each recipe one by one if the number of recipes is increasing. So I would still need to use a job_builder for it. Is trere any solution?
As I said Scenarios is the solution. A Scenario doesn't have to be scheduled or have any triggers, it can be created and executed manually at will. You can run a scenario via API calls synchronously or asynchronously, your choice. Finally a Scenario doesn't have to build all datasets downstream or upstream, it can build whatever you want. You can set the Build mode in your Build step to "Build just these items" and if you just add one dataset to each Scenario build step you will have the sequential build that you want.
I have tried using Scenarios but I still encounter the same problem. I have built 2 scenarios with the following details :
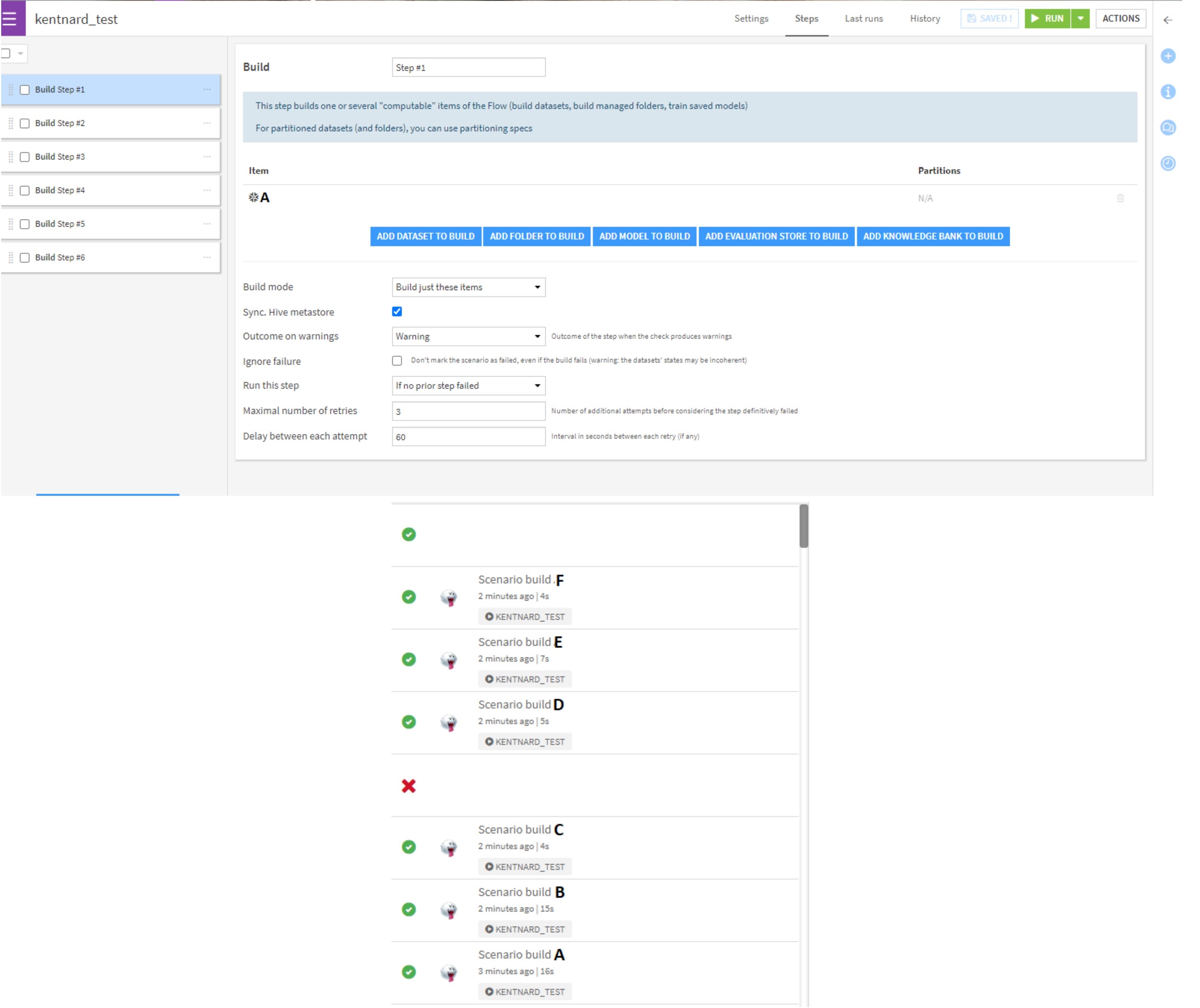
1. Scenario 1 (See attachment "Scenario + Job 1")
I created a scenario with multiple steps. Each step would only build one dataset that I want. The result can be shown in the Job tab, and it shows 6 jobs being executed separately. The order of the recipes that I want to execute is correct, since I ordered them in the scenario.
However, this only works fine with low number of recipes (in this case 6), but there are some instances, where I would like to execute 50+ recipes, and this will not look appealing in the Job tab and makes it difficult to manage.
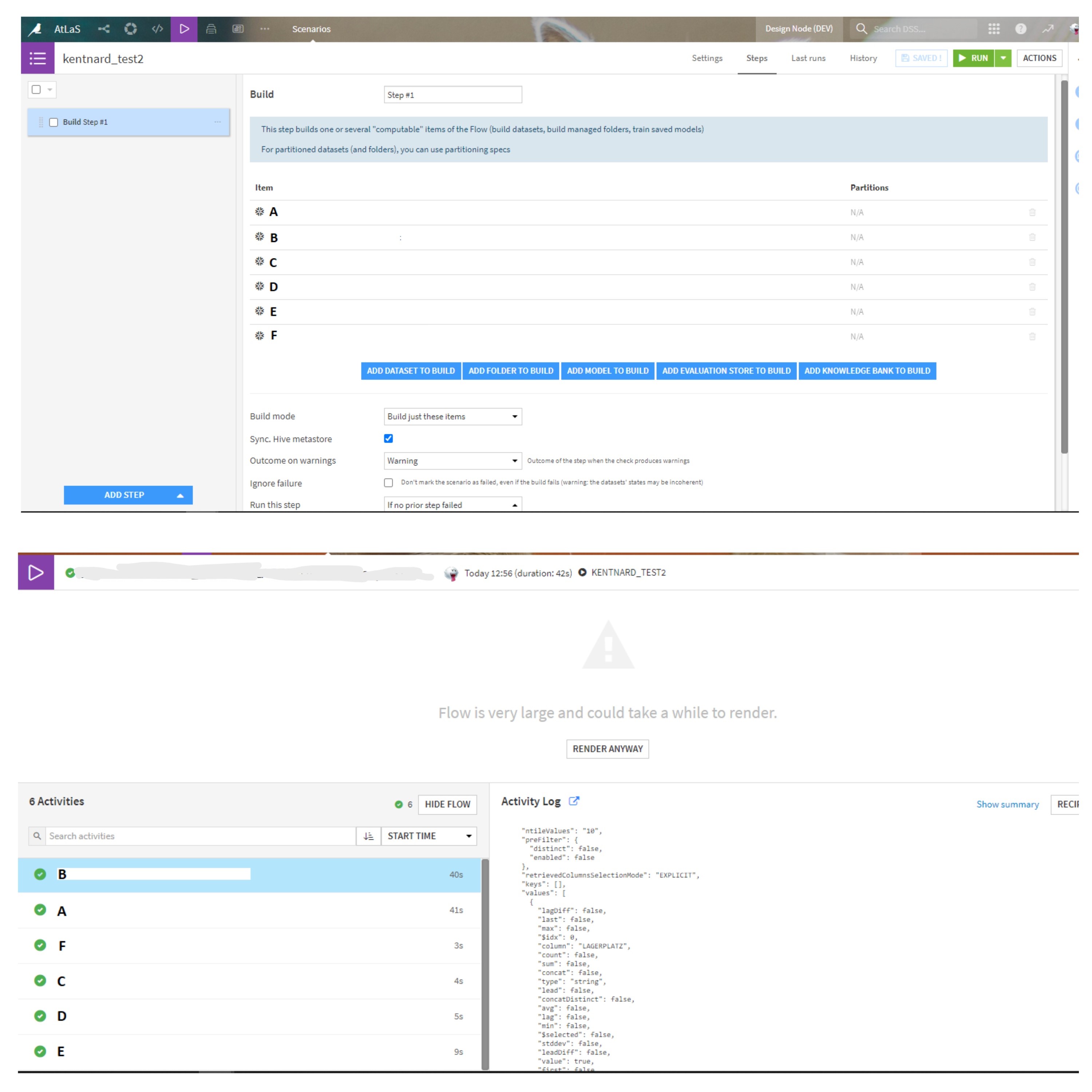
2. Scenario 2 (See attachment "Scenario + Job 2")
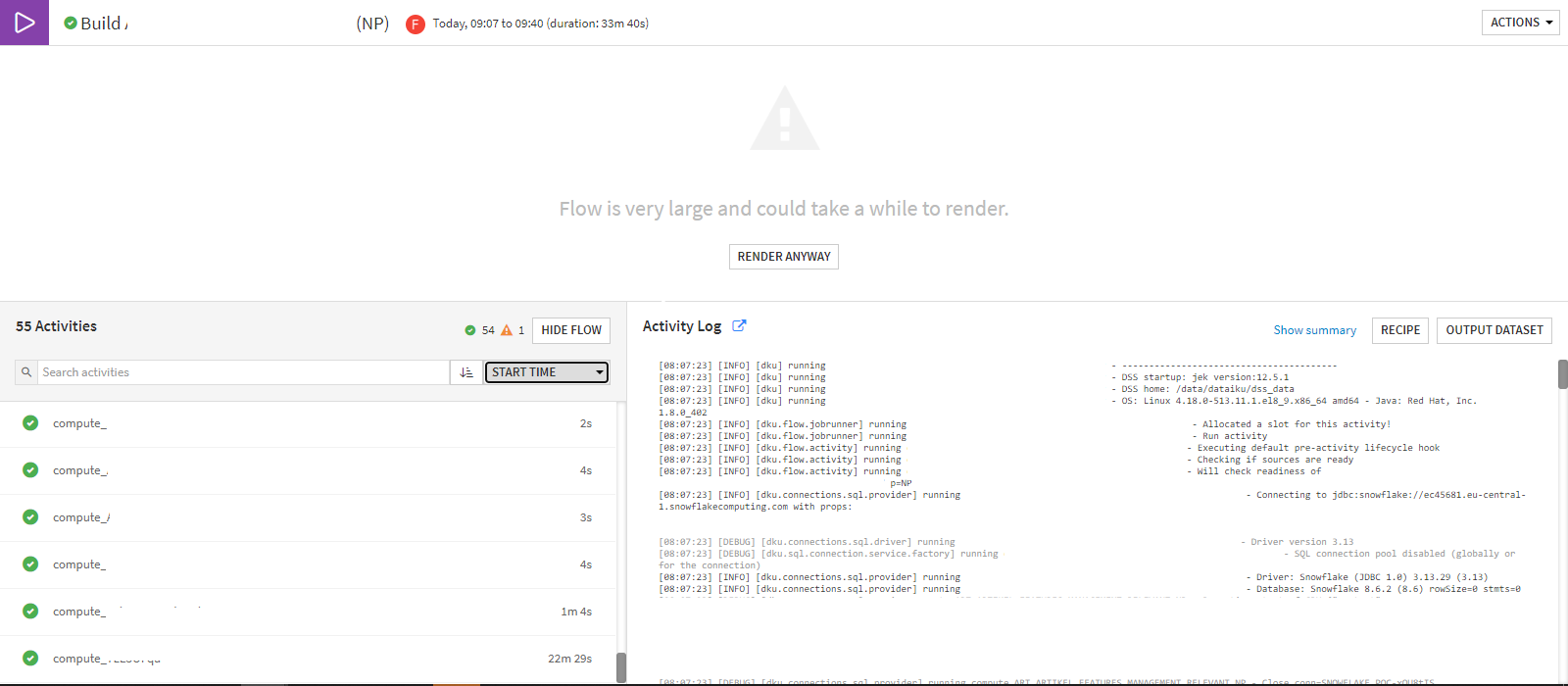
I built a 2nd scenario, where I only had one single steps, but contains all datasets to be built. I have set the order of the datasets as well (the same order as in Scenario 1). The outcome can be seen in the Job tab and it is only "one" job that is executed.
However, when I look deeper into the job, the recipes are run parallelly. It can be seen in the screenshot that it is not in the same order I have defined in the scenario.
So, both scenarios did not do what I intend them to do. I want to the recipes to be executed sequentially (like in Scenario 1) and outputs only "one job" (like in Scenario 2). This is what I wanted to achieve in the first place with the job_builder. How would I be able to achieve this? (either with job_builder or Scenario)
Thank you in advance.
Hi, before I go further with any assistence it will be good to understand:
Hello, to answer your questions :
I think using jobs you are never going to achive what you want and indeed is not even the right tool for the job (pun intended!).
With regards to using scenarios you already have a solution that executes things the way you want but you don't like how the information is presented in the scenario Last Runs tab. Personally I don't think this is an issue that's worth persuing, at least as far as how things look. Having said that I do think that having a scenario that only has a single dataset build per step is a bit of an anti-pattern and goes against how scenarios should be used in Dataiku. More importantly this scenario design will not be able to execute any jobs in parallel which depending on your flow design may lead to very poor performance of your custom build jobs as each job has to wait for the previous one to execute.
And therein lies the problem of this whole thread: your requirement to execute "jobs sequentially" is not a real requirement but how you thought you could solve your real requirement: to build some flow datasets in the correct order. Once you understand what the real requirement is this usually results in a much better solution since you are not trying to go against the flow (second pun intended!).
So here comes the last solution I will propose and I will declare myself out of this thread. They key of your problem is to understand that you will have the best outcome using the smart flow execution which allows you to specify your end of flow output datasets and set to run all downstream recipes in the right order and in parallel if possible. You will of course say you don't want to run your whole flow and you want to exclude some datasets. That should be what your question should have always been about (see this).
The solution to your requirement is there to create a scenario with 3 steps:
dataiku_client = dataiku.api_client()
project = dataiku_client.get_project(project_key)
dataset = project.get_dataset(dataset_id)
dataset_settings = dataset.get_settings()
dataset_settings.get_raw()['flowOptions']['rebuildBehavior']='WRITE_PROTECT'
dataset_settings.save()2) You then add a build a step with all your end of flow output datasets and set it to run all downstream recipe
3) Finally you add a final Python code step to revert the datasets you changed in step 1 back to normal build mode:
dataiku_client = dataiku.api_client()
project = dataiku_client.get_project(project_key)
dataset = project.get_dataset(dataset_id)
dataset_settings = dataset.get_settings()
dataset_settings.get_raw()['flowOptions']['rebuildBehavior']='NORMAL'
dataset_settings.save()
You execute this scenario and you will have a flow build scenario which will build all the datasets you want, in the correct order and in parallel where possible and in a single job/scenario step.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}