Sign up to take part
Registered users can ask their own questions, contribute to discussions, and be part of the Community!
Registered users can ask their own questions, contribute to discussions, and be part of the Community!
We wanted to make GKE integration possible from notebook, my question is:
1) do we need to create and push the image first to the registry separately for notebook operations.
2) What all kind of execution is possible from notebook, example: python and pyspark? as I wanted to submit it to the GKE cluster directly from notebook.
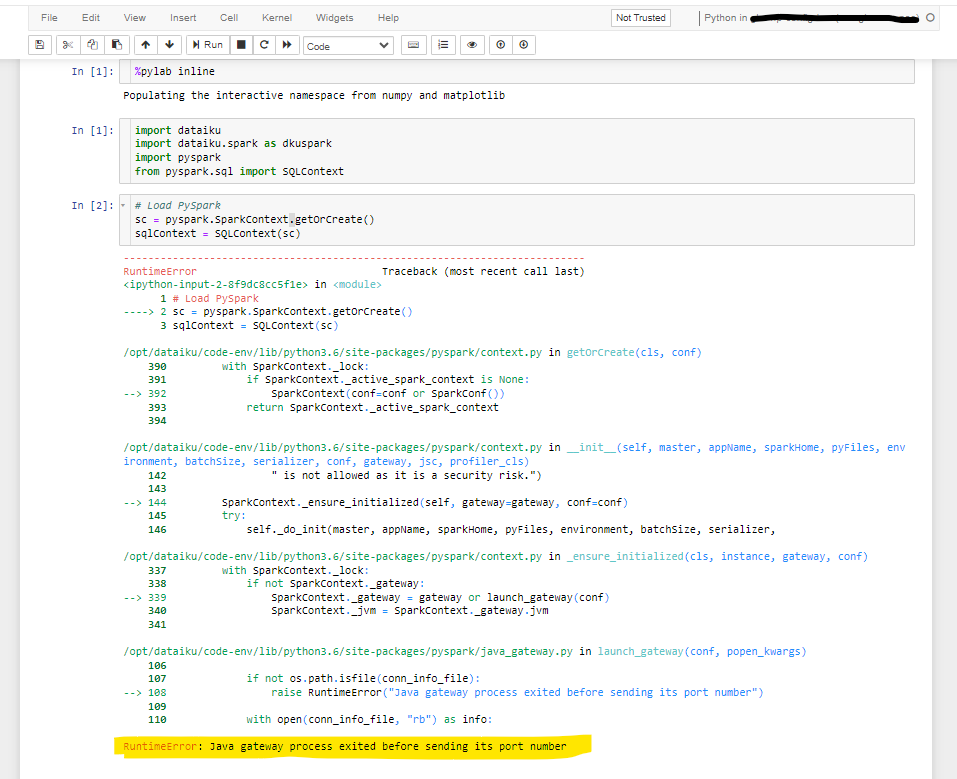
3) Currently, when I tried to run the pyspark base code from notebook, it is throwing error, which means we have to set JAVA_HOME somewhere, would you please help me where to set this, do consider I am submitting load from notebook to GKE.
Error I am getting from pyspark code: I checked the pods logs on GKE it says JAVA_HOME is missing.
RuntimeError: Java gateway process exited before sending its port numberPlease help.
Operating system used: rhel8
Hi @igour ,
A few points, if you want to execute a job on your GKE cluster, you would need to meet a few pre-requisites as detailed here:
https://doc.dataiku.com/dss/latest/containers/gke/index.html
In summary you need the Cluster configured, Containerized Execution config , Base images built and pushed.
Once you have GKE cluster configured with containerized execution config, you need to make sure the code env you plan on using in your notebook has containerized execution config associated with it ->
If you plan on using code environment for Spark you will need to include Build for Spark K8s configuration options as well
1 For the Python notebook, you can select this Kernel with the code env and config name or when creating the notebook and the notebook kernel will start directly in your GKE cluster.
2) For PySpark Notebook, you will need to run locally on the DSS instance( Select a kernel without the config name) the notebook needs to connect to spark-submit on the local DSS instance.
However, the actual Spark Executors will start in your GKE cluster when you initialize the Spark context ( https://doc.dataiku.com/dss/latest/code_recipes/pyspark.html#anatomy-of-a-basic-pyspark-recipe)
The configuration of the spark executors is controlled globally from the Administration - Settings - Spark
But you can override these in your Spark Context https://doc.dataiku.com/dss/latest/code_recipes/pyspark.html#anatomy-of-a-basic-pyspark-recipe
Thanks,
Thank you @AlexT, for making it so clear.
Also wanted to understand, when we need following Spark setup need to be done.
https://doc.dataiku.com/dss/latest/containers/setup-k8s.html#optional-setup-spark
Rest two we have already taken care of in existing setup(do correct me if I am missing something here).
./bin/dssadmin build-base-image --type container-exec
./bin/dssadmin build-base-image --type spark
Correct, you need to install the base images for spark and the spark and hadoop integration, as mentioned in the doc you referenced.
E.g
./bin/dssadmin install-hadoop-integration -standaloneArchive /PATH/TO/dataiku-dss-hadoop3-standalone-libs-generic...tar.gz
./bin/dssadmin install-spark-integration -standaloneArchive /PATH/TO/dataiku-dss-spark-standalone....tar.gz -forK8S
You can download these from ( replace your DSS version) in the URL
https://downloads.dataiku.com/public/studio/12.2.1/dataiku-dss-hadoop-standalone-libs-generic-hadoop...
https://downloads.dataiku.com/public/studio/12.2.1/dataiku-dss-spark-standalone-12.2.1-3.4.1-generic...
Note these steps are not required if you are on Cloud Stacks deployment you can just add SETUP_K8S_AND_SPARK in your instance template
If you have any further issues with your setup I would suggest you open a support ticket with spark job diagnostics + instance diagnostics to understand potential notebook failure reasons.
Thanks



{kind=link}