Sign up to take part
Registered users can ask their own questions, contribute to discussions, and be part of the Community!
Registered users can ask their own questions, contribute to discussions, and be part of the Community!
Hi,
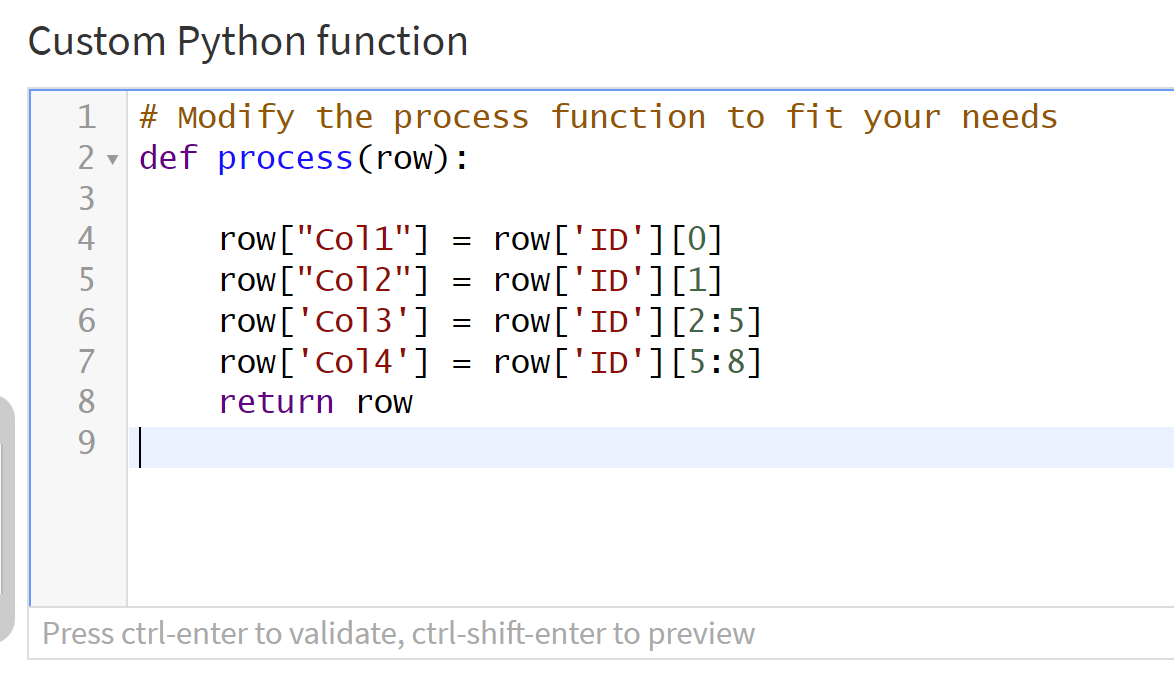
I have the ID data in one column, example, AB123456, and I want to split into 4 columns,
Column 1 is first character
Column 2 is second character
Column 3 is third, forth & fifth characters
Column 4 is sixth, seventh & eighth characters
Dataiku has a fonction to manage it?
Thanks in advance;
Hi Brenda,
Using the Python function (doc) in the Prepare recipe and setting it to 'row' mode allows you to do this pretty easily!
What @LouisDHulst has suggested looks like it will work. (I've not tested it.)
As an alternative you might also try an "Extract with Regular Expression" Step within a visual recipe.
In the case you were asking about I used this regular expression pattern. This creates all of the columns in a single visual recipe Step.
(.)(.)(...)(...)
In this regular expression the open and close parentheses "( )" denotes a block of text that should become a column in the output.
The period "." denotes any single character. Multiple periods can be used to reference any number of characters.
You can use the Smart Pattern tool to extract single columns as well.
Regular Expressions or Regex is a sophisticated and some time frustrating bit of text processing software that can process your ID column with remarkable sophistication if you take the time to learn Regular Expressions. Learning Regular expressions can be a valuable skill. Beyond Dataiku's Smart Pattern tool, there are a number of online regular expression learning tools like https://regexr.com/ that can help you learn regular expressions and formulate useful regular expressions.
Here is the step I made showing the results that I have.
That said, if I were to use this in production I might use a different more specific expression designed to deal with common error states.
For example a regular expression like this is very particular and will reject things that do not match what we expect:
^(\w)(\w)(\d\d\d)(\d\d\d)$
From the beginning denoted with the "^"
Finds a word character, (\w) and put it in a column
a second word character (\w) and put it in a column
and two 3 digit strings (\d\d\d)(\d\d\d) and put each 3 digit string in their own column.
And the field must end there denoted by the "$"
If the data is not formatted in exactly this way we will return blank results. This may actually be to picky depending on your source data. It's up to you to write an expression that meets your needs.
There are an almost unlimited set of choices you can make in parsing a field like this with different levels of insistence on exact matches.
Hope this might help you or someone else here in the community.
This is a much better way of doing it! But RegEx...
Yes,
What can I say? Regx is super powerful. (and at the same time mind bending.)
Good luck. Let us know how you get along with this.
P.S. You can also Grok
https://doc.dataiku.com/dss/12/preparation/processors/grok.html
Or use formula steps, that slice out different character ranges.
https://doc.dataiku.com/dss/12/formula/index.html
You may have to do multiple steps to create each of the columns you need.
If your data is in a sql database you could write this is an SQL query.
Although, the Regex way is fast and compact. (And maybe showing off a bit... 😎)
Hope you have worked out your situation.

{kind=link}