Sign up to take part
Registered users can ask their own questions, contribute to discussions, and be part of the Community!
Registered users can ask their own questions, contribute to discussions, and be part of the Community!
I am trying to run a complex query on a SQL dataset. However, it just takes around 40 min to run. What can I do to run it faster?
Hi,
It is hard to help you without detailed information:
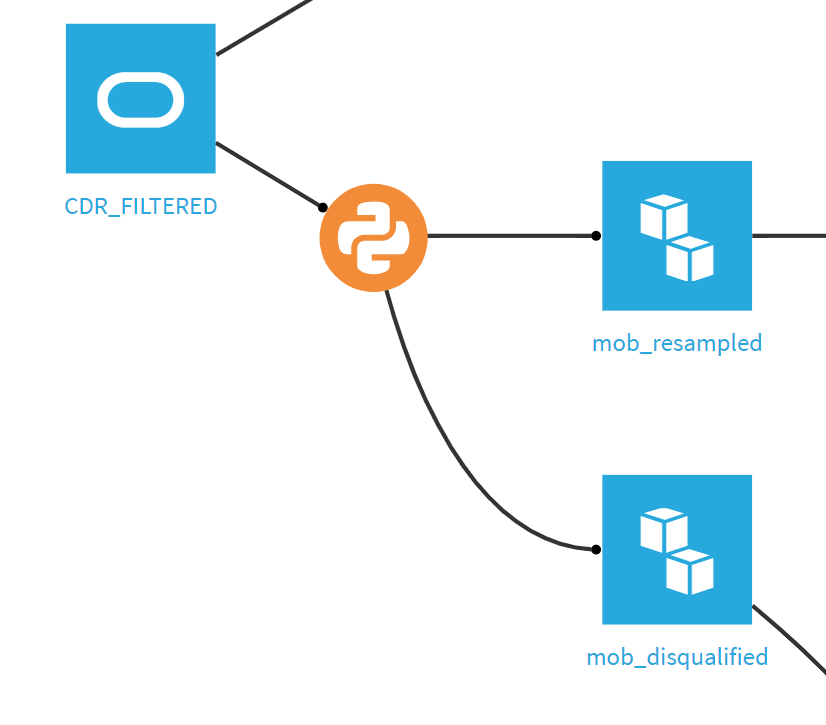
It would help if you screenshot that part of your flow.
Best regards
1. Around 440 million rows
2. It is a SQL recipe that first does a SUM group by, then takes a MAX, and then applies a FILTER on the value of MAX
3. For Input, it is Oracle RDBMS. I am creating a SQL dataset based on a SQL query in settings.
4. I think it is running the query in database itself, right?
Hi,
So, it seems that your input dataset is an SQL query. Did you see the attached warning? Instead, it is recommended that you setup a view that fits your needs in your database.
What is the data connection of the output? Recipes with different input and output connections will likely run on the DSS engine itself.
On the current engine, I suspect because of your setup, the recipe is not running on the database itself, but on the DSS engine. Check the options on the cog near the run button. What does it say its running? Local?
If possible,please take a screenshot of that part of your flow.
I hope this helps.
Hi,
One suggestion is that you use first Sync your source dataset (the SQL Query) into an S3 dataset, which will then be the input to your Python recipe. This way you won't be running the Oracle query every time you test your Python recipe.
On the performance of the SQL query iteself, I am afraid there is not much you can do. It is a heavy query, so it will take time to run.
I hope this helps.
I tried to do it but the number of rows is more than 100 million and it takes a lot of time to do it. It uses DSS engine(RUN on stream).
Is there a faster way to do it?
The database is Oracle.
Hi,
I am afraid there are no fast paths between Oracle and S3.
How large is the whole table you define the SQL query dataset on? Instead of the SQL Query dataset, have you considered using the whole table as the input dataset, followed by a recipe that selects the relevant rows, followed by the remaining logic
This would also allow you to use partitioning, processing the data in chunks.
I don't know what your use case is, but it seems worth to engage your Customer Success Manager and other services to have a closer look and help you optimise.
Best regards
Best regards
Bu the partitioning column is a derived column, so I cant use it to create partitions in SQL dataset.
You should be able to use existing columns for SQL partitioning.

{kind=link}
{kind=link}