Sign up to take part
Registered users can ask their own questions, contribute to discussions, and be part of the Community!
Registered users can ask their own questions, contribute to discussions, and be part of the Community!
Is there a way to setup user-level environment variables? I know that we can setup dataiku user variables, but what I was looking for is more about environment variables seen by non-dataiku applications that are used within Dataiku. I know this may sound confusing, so here is my use case:
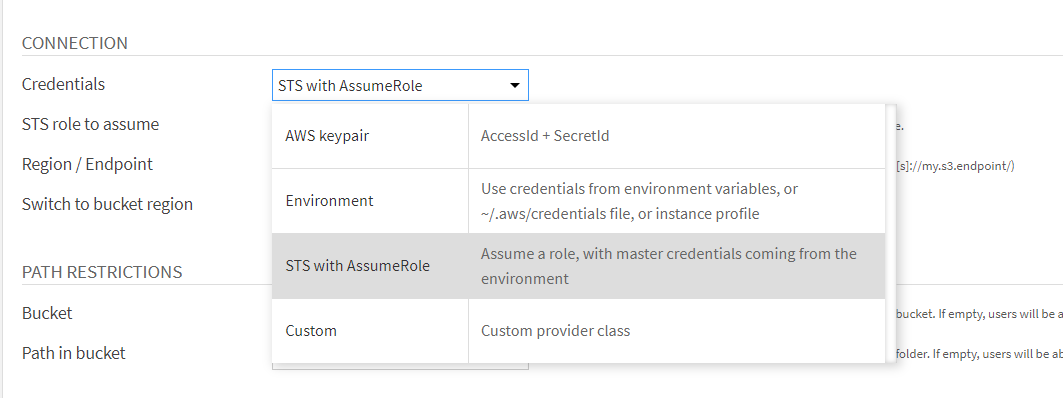
I want to setup a cross-account S3 bucket connection, for that I need to use the "STS with AssumeRole" credentials to assume the cross account role that enables me access to the bucket in the other organization. This all works great.
The problem here is that the user "master" credentials that are used when issuing the "Assume Role" command are picked up from the environment (Dataiku restriction), which means it's unified for all users, so for example we either have to setup the AWS Access key and secret key as dataiku-user env variables, put them in ~/.aws/config or setup access using Instance metadata. This also means that when we want to ask for access to this bucket that is in another organization, we would have to request access for this "god-user" and there is no way to track who has access and who doesn't.
That's why I thought if the user can enter his own credentials (same way that per-user connection credentials for DBs work) then we can fix this issue because then cross-account access can be granted at the specific user level. This is however not supported in Dataiku, because if you want to use STS AssumeRole, the master credentials have to be read from the environment. That's why I was thinking about user-level environment variables so that this would then be transparent to the AWS SDK.
One big precondition here of course would be the activation of the UIF so that each user would have his own login and runs his own isolated code, but we already have that in place (with LDAP), so technically (on an os-level), it should be possible to define user-level env variables and have dataiku pick them up when it executes isolated code. My only question is it possible to define such environment variables with Dataiku
Sorry for the long question and I hope I explained my use case well enough. If there's a better way to implement my use case, please let me know. Thank you
Hi,
In the specific case of environment variables, this would be impossible. Environment variables are process-wide, and it's not possible to have "sub environment variables" within the DSS backend.
To achieve your goal, there are two main avenues in DSS. Both require UIF to be enabled in order to provide proper isolation:
The second solution would be the prefered one:
With this setup, each time a user A, DSS will get the "impersonating" credential from ~/.aws/credentials (accessible only to DSS, not to A), will lookup the admin property iamRoleToAssume from the settings of user A, call the STS AssumeRole AWS API in order to retrieve a STS session token in the name of iamRoleToAssume and then perform all operations with this session token.
With this setup, users do not have to have any AWS keypair and do not need to manage its lifecycle. You also avoid having a single IAM role that is all powerful, since everything is done by first going through STS, reducing the risk of leaking dangerous permanent credentials.
Hello @Clément_Stenac how about when using sso login (profiles) not credentials in aws?
If I create a connection in to s3 using STS Assume role (role of s3) when I set per user. How can I authenticate a user action? For example say, user Arnaud access this bucket yesterday cloud governacne use case.
Thanks
Hey Clément
Thanks for the reply, please correct me if I am wrong, with your 2nd solution, this "master" account whose credentials we put in ~/.aws/credentials would still have to be assigned the AssumeRole policy for all the possible cross-account roles that we would want our users to be able to assume (In the example below, we would have policies for "MyDeveloperAccess", "MyManagerAccess", ..... assigned to this one account) because otherwise it wouldn't be possible to use it to impersonate those roles.
Which one of those roles a dataiku user would actually assume would be determined by the admin property. This also means that anyone with access to this master account would be able to assume any of those roles, is that correct?


{kind=link}