Sign up to take part
Registered users can ask their own questions, contribute to discussions, and be part of the Community!
Registered users can ask their own questions, contribute to discussions, and be part of the Community!
Hello,
Does anyone know how to generate a scatter plot where the points of a given data set are linked?
This way, interpreting the trends wil be easier, as I have several data sets on the same graph.
Thanks in advance for your help.
Olivier
Hello @OlivierW!
The Dataiku engine to draw Pivot graphs does not exactly works that way. You must imagine that each line represents a different graph, so even so a line is made of 30 points, the other 320 points are set to 0, meaning there are no values for this coord.
You can see a little bit more on how elements are counted in your browser inspector > Network, and searching for "get-pivot-response". Thus, the number of elements is #series * #sampling_in_x_axis.
For example, if you have a dataset containing one row per each day of 2020 (365 rows) and each row is discriminated in one of 29 different values. Well the x axis will have 365 different values, and the total number of elements will be 365*29 = 10,585 elements. However, let's say that one of the values is from the 1st of January 2019, well the x_axis will not have 365 values but 730 as it will go through all the values between 2019-01-01 and 2020-12-31. Does it make sense?
Hello Olivier,
It is currently not possible to link the points on a scatter plot. However, you can use another type of graph, Lines, that will draw a line for each of your columns.
Would it be enough for what you can do?
Have a nice day,
Henri
Hello Henri,
I am plotting a column as a function of time, but on the scatter plot graph, I use the "Details" field to plot several data sets. This field does not seem to be available on the line plot. Is it correct?
Thanks,
Olivier
Hi,
You can select multiple columns in the Y axis for the Line plot. That way, you will be able to represent several plots on the same graphs coming from different columns.
Are your data really in seperate Dataiku Datasets or are they in the same dataset but in different columns?
Hello Henri,
All the info used for my plot is in a single dataset.
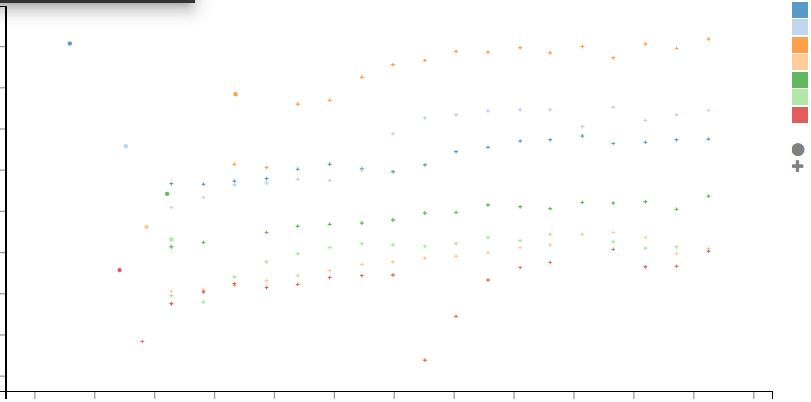
I plot the data of say, column B as a function of column A. But I create subsets within the values of column B depending on the value in column C : a point has a colour that depends on the value in column C, as shown in the example attached.
Olivier
Thanks for the precision!
In that case, you have to use the field "And" to split your data based on another column (See screeshot) But it will only work for one column. If you need to discriminate by more than one column, it is unfortunately not possible and you will have to use Scatter plot, or to use a prepare recipe to gather all discrimination in one and only one column.
Does this make sense?
Hi Henri,
Thanks for your reply, I am getting closer indeed!
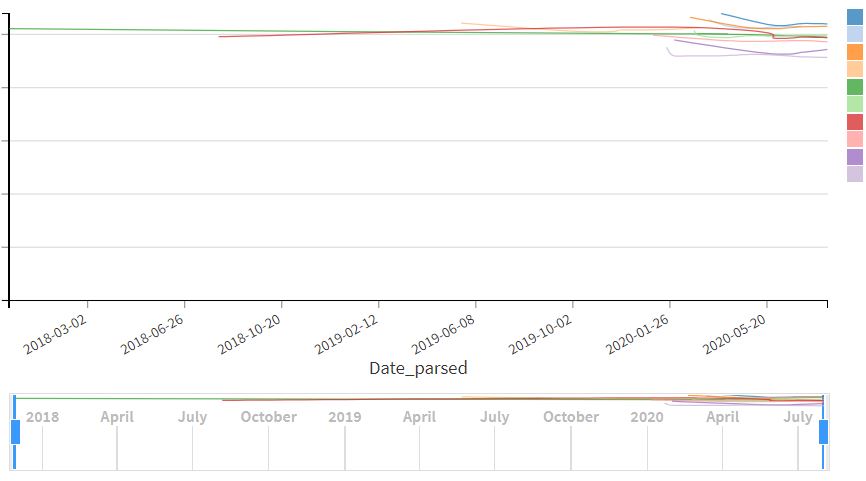
By selecting a part of the entire column (with the filter function), I have been able to plot column B as a function of column A, with one line on the chart for each value of column C (as shown in file "Capture 2").
The two questions remaining are :
- Is it possible to specify the scale on the Y axis? It starts at 0 at the moment which makes the chart hard to read (all the data is crammed at the top)
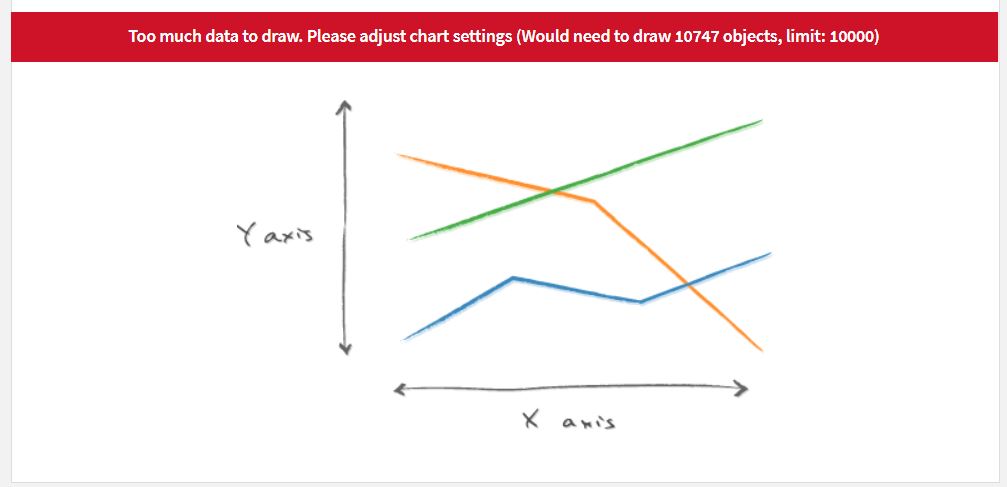
- I hit a limit of chart capacity if I try to plot my entire dataset (error message shown in file "Capture 3"). The dataset is not very big though (343 lines, and 29 different values in column C, so 29 lines on the chart). I can get the plot to display without error if I select data corresponding to 10 to 12 values of column C
Do you know how to get around these issues?
Thanks,
Olivier
Hey Olivier!
- Unfortunately, it is not possible to change the scale for that type of charts. The only solution I see is for you tu use a prepare recipe that normalizes the data. You can then use the Tooltip field to seee the original value.
- The limit of 10,000 objects cannot be increased and represents the number of points points represented on the chart. There is no real workaround for this limitation.
Have a good day,
Henri
Hi Henri,
Thanks for your first idea, I will try.
On the second point (limit of objects), I am surprised, because the total number of points is only 340 points (the number of lines in the column B), distributed in 29 series (29 distinct values in column C). Do you know how the number of objects is counted?
Thanks,
Olivier
Hello @OlivierW!
The Dataiku engine to draw Pivot graphs does not exactly works that way. You must imagine that each line represents a different graph, so even so a line is made of 30 points, the other 320 points are set to 0, meaning there are no values for this coord.
You can see a little bit more on how elements are counted in your browser inspector > Network, and searching for "get-pivot-response". Thus, the number of elements is #series * #sampling_in_x_axis.
For example, if you have a dataset containing one row per each day of 2020 (365 rows) and each row is discriminated in one of 29 different values. Well the x axis will have 365 different values, and the total number of elements will be 365*29 = 10,585 elements. However, let's say that one of the values is from the 1st of January 2019, well the x_axis will not have 365 values but 730 as it will go through all the values between 2019-01-01 and 2020-12-31. Does it make sense?
Hi Henri,
Yes it makes sense. Thanks for the precisions.
Have a nice day.
Olivier


{kind=link}
{kind=link}
{kind=link}