Sign up to take part
Registered users can ask their own questions, contribute to discussions, and be part of the Community!
Registered users can ask their own questions, contribute to discussions, and be part of the Community!
Hello
I start with Dataiku and try to fill the empty lines of a column with the last non-null value taken by the column.
I work on Dataset HDFS partitioning per day.
I have already tried the visual recipe "Fill empty cell with previous value".
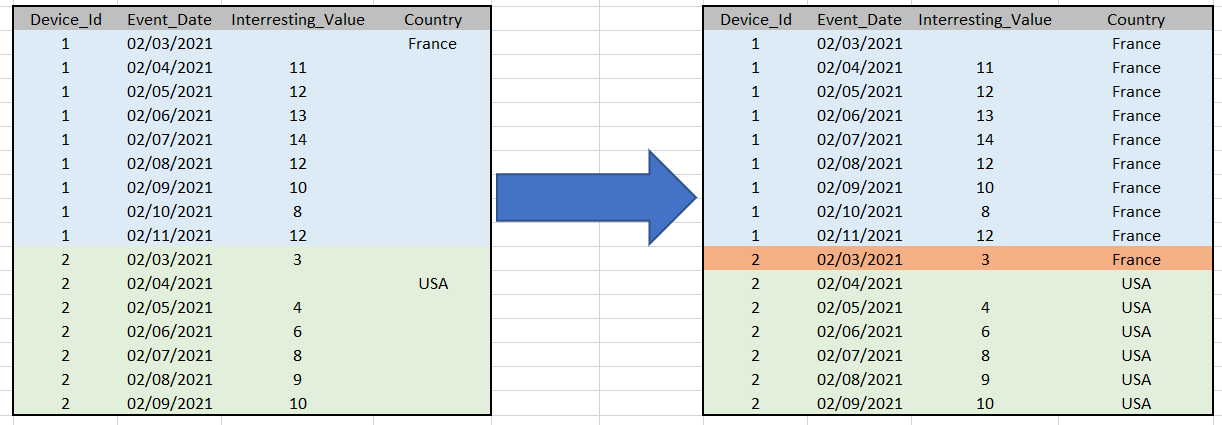
Unfortunately as you can see in the attached picture; I would have liked this filling to be done only under the condition of an equivalence (here on the Device_Id , the red line is what I would like to avoid)
I suspect that by doing a "Custom aggregation" in a "Windows Recipe" it should be possible. Unfortunately I can't do it.
If someone has already encountered this problem and has a solution, I would be happy to get some help.
Thanks,
AV
Hi @Avalo ,
There are likely several ways to accomplish this, but I'll provide one option using a Python recipe.
Here I created a sample dataset like you provided in your screenshot:
I created the following python recipe and utilized the pandas groupby in combination with the fillna option to forward fill the country values within the "device_id" group. The other fill options can be found here.
import dataiku
import pandas as pd, numpy as np
from dataiku import pandasutils as pdu
# Read recipe inputs
sample_data = dataiku.Dataset("sample_data")
sample_data_df = sample_data.get_dataframe()
# -------------------------------------------------------------------------------- NOTEBOOK-CELL: CODE
# Compute recipe outputs from inputs
python_window_df = sample_data_df # For this sample code, simply copy input to output
# -------------------------------------------------------------------------------- NOTEBOOK-CELL: CODE
# this is the main transformation. It updates the "country" column to group by the device_id column and forward fill country values within that group
python_window_df['country'] = python_window_df.groupby('device_id')['country'].fillna(method='ffill')
# -------------------------------------------------------------------------------- NOTEBOOK-CELL: CODE
# Write recipe outputs
filled = dataiku.Dataset("filled")
filled.write_with_schema(python_window_df)
Here's my output dataset, where the offending row you point out is now still NULL. This could be adjusted based on the fill method.
Hope that helps.
Thank you,
Sarina
Hi @Avalo ,
There are likely several ways to accomplish this, but I'll provide one option using a Python recipe.
Here I created a sample dataset like you provided in your screenshot:
I created the following python recipe and utilized the pandas groupby in combination with the fillna option to forward fill the country values within the "device_id" group. The other fill options can be found here.
import dataiku
import pandas as pd, numpy as np
from dataiku import pandasutils as pdu
# Read recipe inputs
sample_data = dataiku.Dataset("sample_data")
sample_data_df = sample_data.get_dataframe()
# -------------------------------------------------------------------------------- NOTEBOOK-CELL: CODE
# Compute recipe outputs from inputs
python_window_df = sample_data_df # For this sample code, simply copy input to output
# -------------------------------------------------------------------------------- NOTEBOOK-CELL: CODE
# this is the main transformation. It updates the "country" column to group by the device_id column and forward fill country values within that group
python_window_df['country'] = python_window_df.groupby('device_id')['country'].fillna(method='ffill')
# -------------------------------------------------------------------------------- NOTEBOOK-CELL: CODE
# Write recipe outputs
filled = dataiku.Dataset("filled")
filled.write_with_schema(python_window_df)
Here's my output dataset, where the offending row you point out is now still NULL. This could be adjusted based on the fill method.
Hope that helps.
Thank you,
Sarina
Thank you very much for your help.
your solution is elegant and efficient.
Thank you,
AV
Hi @Avalo ,
You may also want to try the "Fill empty cells with previous/next value" processor that's available in the Prepare recipe. It will also let you do what you've described.
Cheers,
Ashley



{kind=link}