Sign up to take part
Registered users can ask their own questions, contribute to discussions, and be part of the Community!
Registered users can ask their own questions, contribute to discussions, and be part of the Community!
Hello,
I ask for your help to create a recipe that would change the number of lines of my dataset. I wish to do the following operations but am enable to create them in dataiku :
My dataset looks like :
Item number | Date | Value |
Item 1 | Date 1 | Value 1 |
Item 1 | Date 2 | Value 2 |
Item 1 | Date 3 | Value 3 |
… | … | … |
Item 2 | Date 1 | Value 1 |
Item 2 | Date 2 | Value 2 |
… | … | … |
The operations I aim to do are :
If anyone can take the time to advise me, I would be grateful!
Have a nice day
Olivier
@OlivierW I think that way you have additional column with the average value for each iteam in each month, without losing orginal value? this is what you are looking for? If yes, then we can use "Prepare recipe" and calculate difference between each value and the average and then remove these values, after that we can use "Group recipe" and group by "month" and "item" again, setting up aggregate value to "AVG" on this dataset.
As for point 1) If you want to calculate average value in a month and ignore item name, just remove item from the window recipe.
Let me know in case any questions
Mateusz
Well, just in case is useful for the future, I implemented @emate solution in a project that I'm uploading here, using a test dataset.
Hi @OlivierW . I think I might help you with this, but I wanted to know first if you want to solve this problem using only Visual Recipes, or is OK to use a Code recipe (python for example)
Hi Ignacio,
Thanks for your reply.
Ideally, I would prefer a solution using dataiku tools if possible, because I don't know Python langage. But if it is impossible, a code recipe would be great too.
Have a nice day,
Olivier
Hi @OlivierW
There are couple of ways to do that.
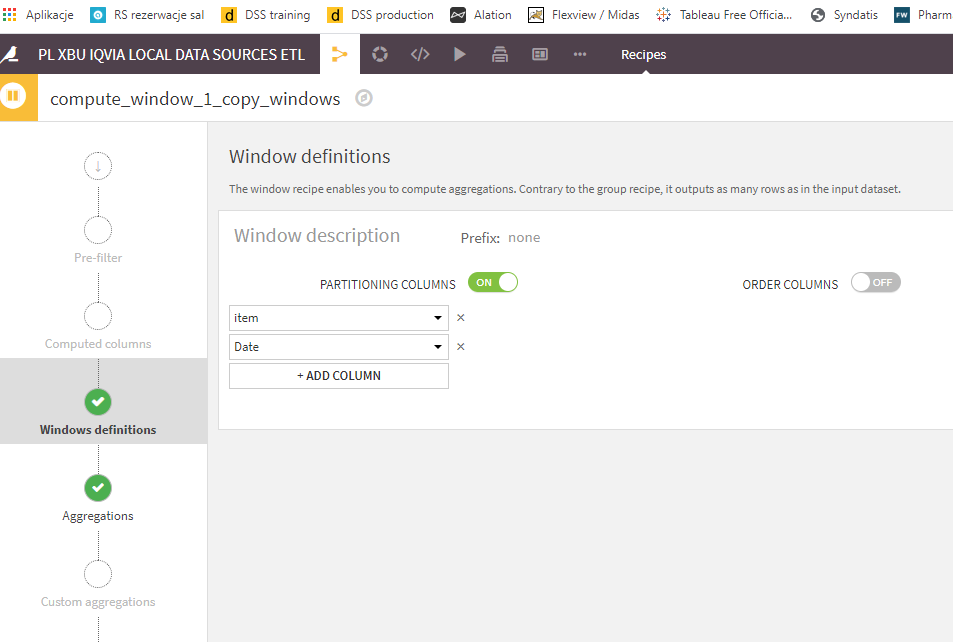
As for your first point, you can use group recipe , but I think in your case better would be a "window recipe" since you want to remove the rows after calculating an average.
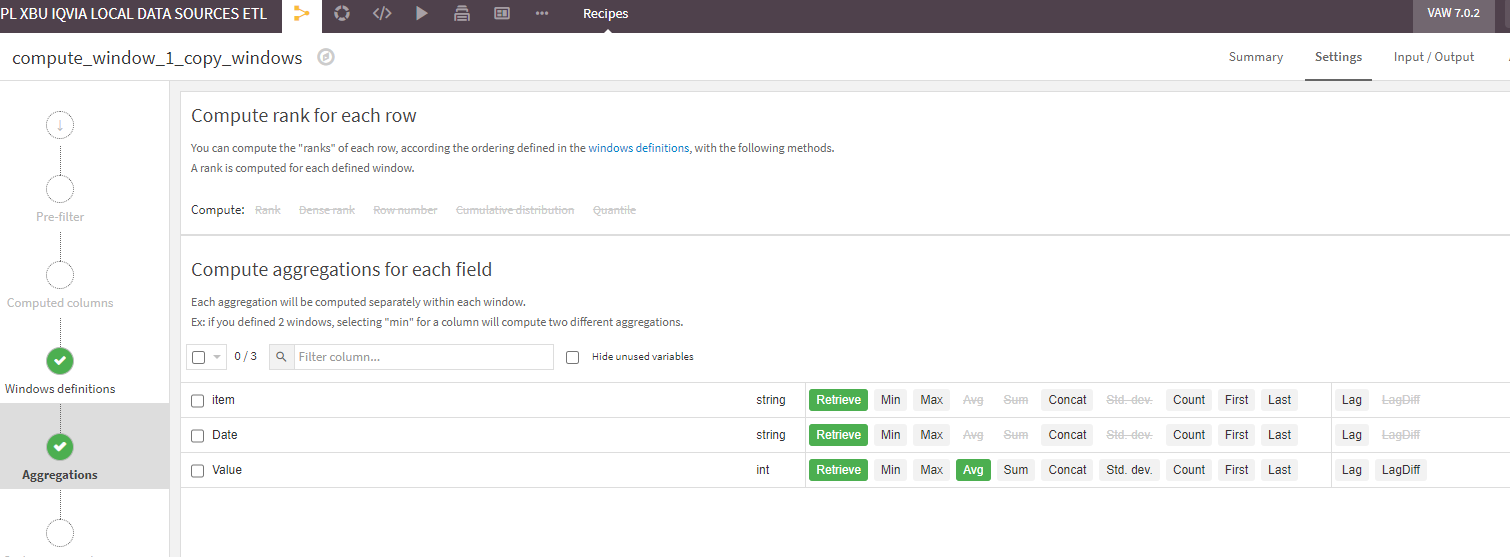
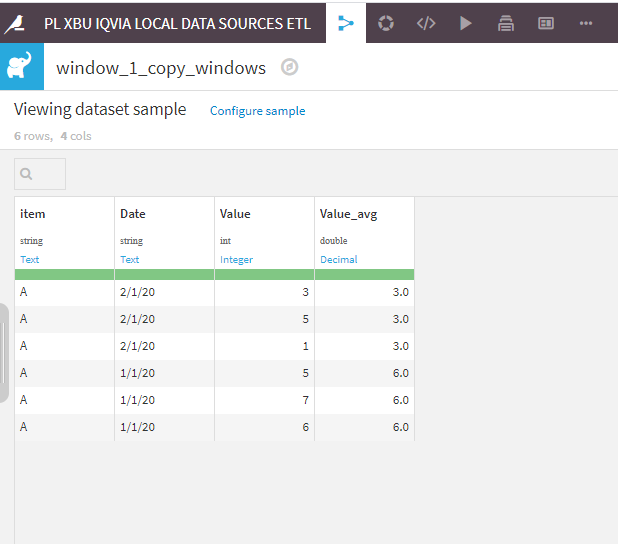
Attached png screen shot, on how to calculate Average for each item in each month.
Could you clarify your second point:
What conditions you want to decide which rows to remove? Like for exmaple looking at "window3.png" I attached which rows you would like to remove in each month? Once we establish that we can just remove these rows and re-calculate an average with the window recipe once again.
For example, when the average is 3, you want to remove the rows where value is 30% higher than the average?
Regards,
Mateusz
Attached screenshots...
Edit: I'm not sure you can open the screenshots, as I see "virus scanning in progress" all the time, in case you can't please use this:
Also I would love to hear what @Ignacio_Toledo think about my way of thinking, maybe he will have a better approach, or can "upgrade" mine 🙂
Mateusz
Hi Mateusz,
Thank you for taking the time to look at my questions.
Unfortunatly, I was unable to open the link (IP adress not found) nor the png files. Can you submit them again?
Also, I think I made a mistake in my description of when I need to change the number of lines in my dataset. A logical way to proceed would be :
1) Add a column returning for each line the average value of the month it belongs to. This average value will be used in step 2) and 3) to establish which lines are too different from the monthly average.
2) Add a column returning for each line the discrepency between the value of the line versus the average value of the month
3) Filter the dataset to keep only the lines where the discrepency (calculated in step 3) is less than x %
4) Create a dataset with only one line per month containing the average value of the month. In step 4, we have a "clean" monthly average because values too different of the average have been filtered out in step 3.
I hope it makes sense.
Kind regards,
Olivier
@OlivierW I think that way you have additional column with the average value for each iteam in each month, without losing orginal value? this is what you are looking for? If yes, then we can use "Prepare recipe" and calculate difference between each value and the average and then remove these values, after that we can use "Group recipe" and group by "month" and "item" again, setting up aggregate value to "AVG" on this dataset.
As for point 1) If you want to calculate average value in a month and ignore item name, just remove item from the window recipe.
Let me know in case any questions
Mateusz
Well, just in case is useful for the future, I implemented @emate solution in a project that I'm uploading here, using a test dataset.
It took me longer to come back to the ticket than I expected. I think your solution @emate is great, specially if no use of code is prefered. Maybe you could share also the 'flow' to see how it looks? Unless for @OlivierW is not necessary.
It would be interesting to have access to more advanced functions when grouping or windowing data. What you are trying to do here is called "sigma clipped average" in astronomy data reduction, and is not a complicated formula. But it is not easy to implement with SQL, which is the only option available when using custom grouping.
Hello @emate , @Ignacio_Toledo ,
Thanks for your advice which was very useful. With the snapshots and the project, I was able to apply it to my dataset. I just add to extract year and month from the date, and use item / year / month for the partition before the calculation of the average. This way, I obtain a monthly average and not a daily one.
Now that I have carried out these steps, I realise I have a further question : given that I have a large number of items, it would be useful for me to calculate the drift of monthly average for each item, namely the variable :
monthly average value of current month - monthly average value of initial month. Could you advise me how to calculate it?
Thanks,
Olivier
@OlivierW
Can you show an example on how the dataset looks like now, and how you want it to look with the addition of this difference in average?
Hello @emate ,
I show below (highlighted in yellow) the column I would like to create. The difficulty for me is that it is not a calculation on a given line of the dataset (for example colum A @ time t1 - column B @ time t1) but a calculation on a given column between 2 different times (the time of the current line and the time of the first data point for this item).
I hope the example is clear.
Olivier
I belive there are couple of ways to do it.
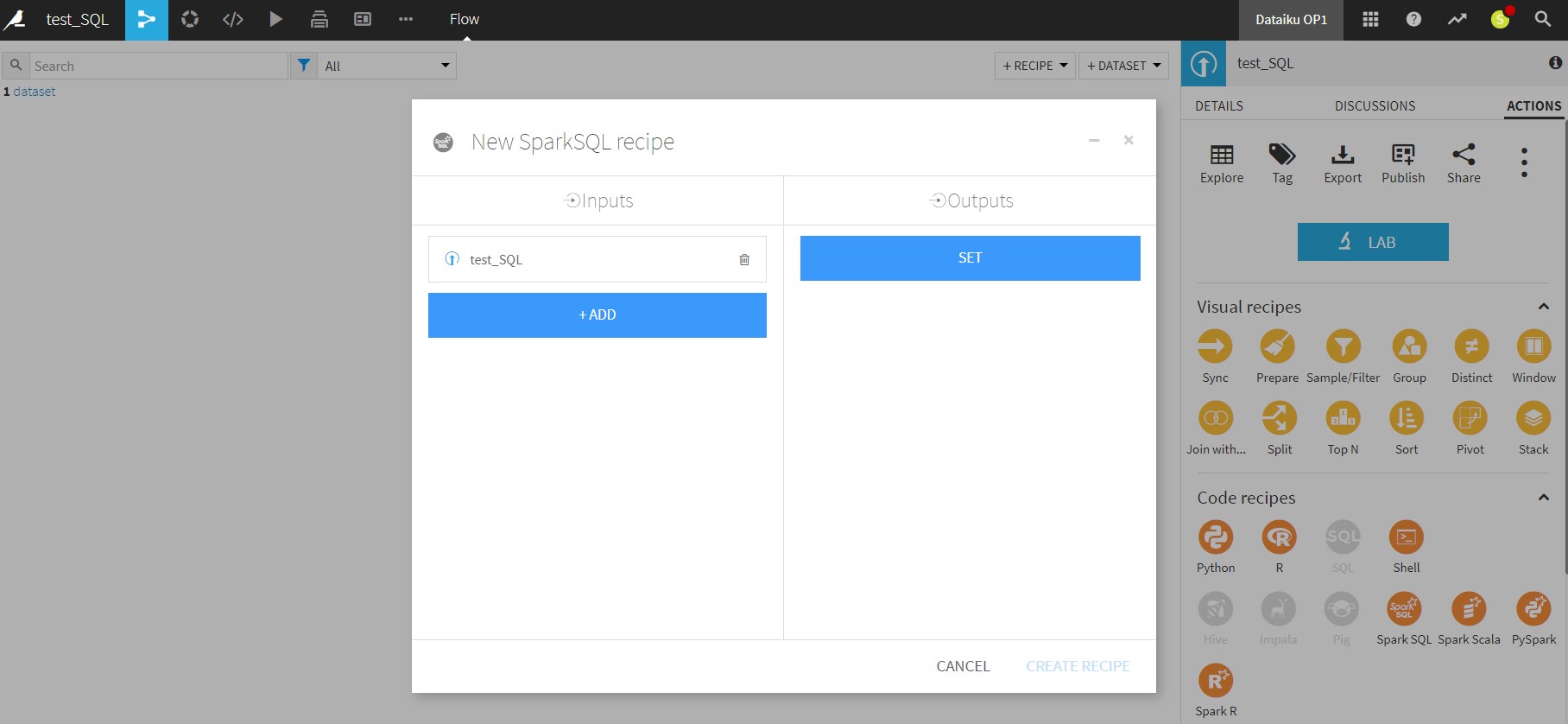
1) I think the fastest way is to use SparkSQL recipe







Hi @emate
Thanks again for taking the time to look at my question.
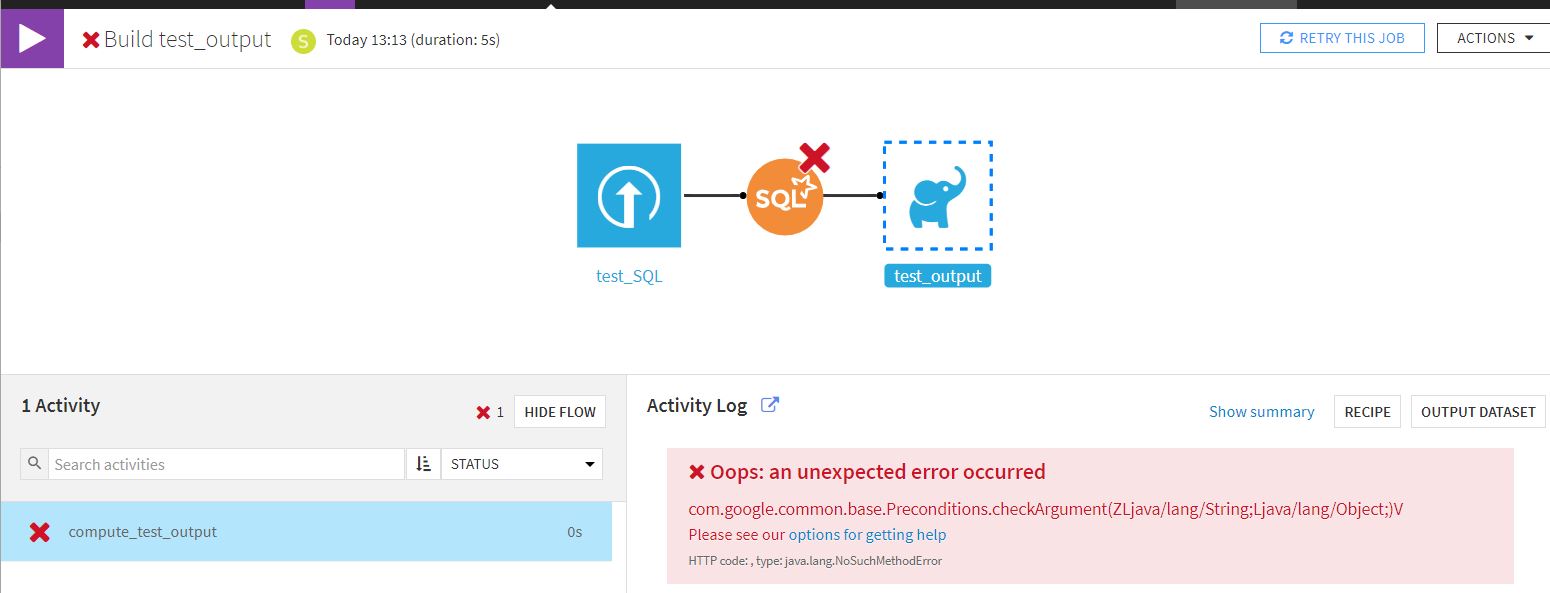
I tried the first solution, but got an error, maybe related to the fact that I had to choose a name for the output which dataiku then could not find?
I attach the screenshots of the steps I followed and the log of the error message below.
Hi @OlivierW
I can think of two reasons, first is brackets or "blanks spaces" in a name of the columns. I had similar issue where i was getting erorrs, so I renamed column to elapsed_days and then SQL script worked just fine - so it might be that.
Other I dont know how you set the output exactly but I do that that way;
Hello @emate
I removed all spaces and brackets from variables, and used the same options as you for the output. I still get an error message. Don't worry though, I have the alternative solution of @Ignacio_Toledo for this step.
Kind regards,
Olivier
To be honest I have no idea why this SQL query is not working in your enviroment, I've tried it 2 times and it worked for me, since you have other solutions that works I will leave it as it is. And you can investigate this issue some other time, as sql queries comes in handy sometimes!
I am uploading the second version of the project I shared yesterday, but now adding the steps to get the table with the change of the average item values as compared to the first month.
In this case, I arrive to the solution in a different way than @emate . And this is the great thing (but sometimes it might be a curse too, if one has bad memory) about the tools available in DSS, which allows you to get to the same answer in different ways.
Cheers!
Hi @Ignacio_Toledo ,
Thanks for your solution, it worked great!











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}