Sign up to take part
Registered users can ask their own questions, contribute to discussions, and be part of the Community!
Registered users can ask their own questions, contribute to discussions, and be part of the Community!
Hello, everyone!
I'm working on a user journey project for a media website I handle. As part of the analysis, I wanted to combine the total time spent on consecutively ranked pages with the same title (e.g. Ranks 6-11). Unfortunately, on Dataiku, when aggregating, Rank 13's total time is added to Ranks 6-11 by virtue of having the same Page Title, even though this is not what I want.
I was told that there might be a solution to this via a Python recipe--to aggregate only rows that (1) have the same title and (2) are consecutive. Would appreciate anyone's input on this, as a beginner data analyst!
Thanks!
Hello @leland_
The following Python code will solve the issue of aggregating by Page Title only when they are consecutive for the example data you gave.
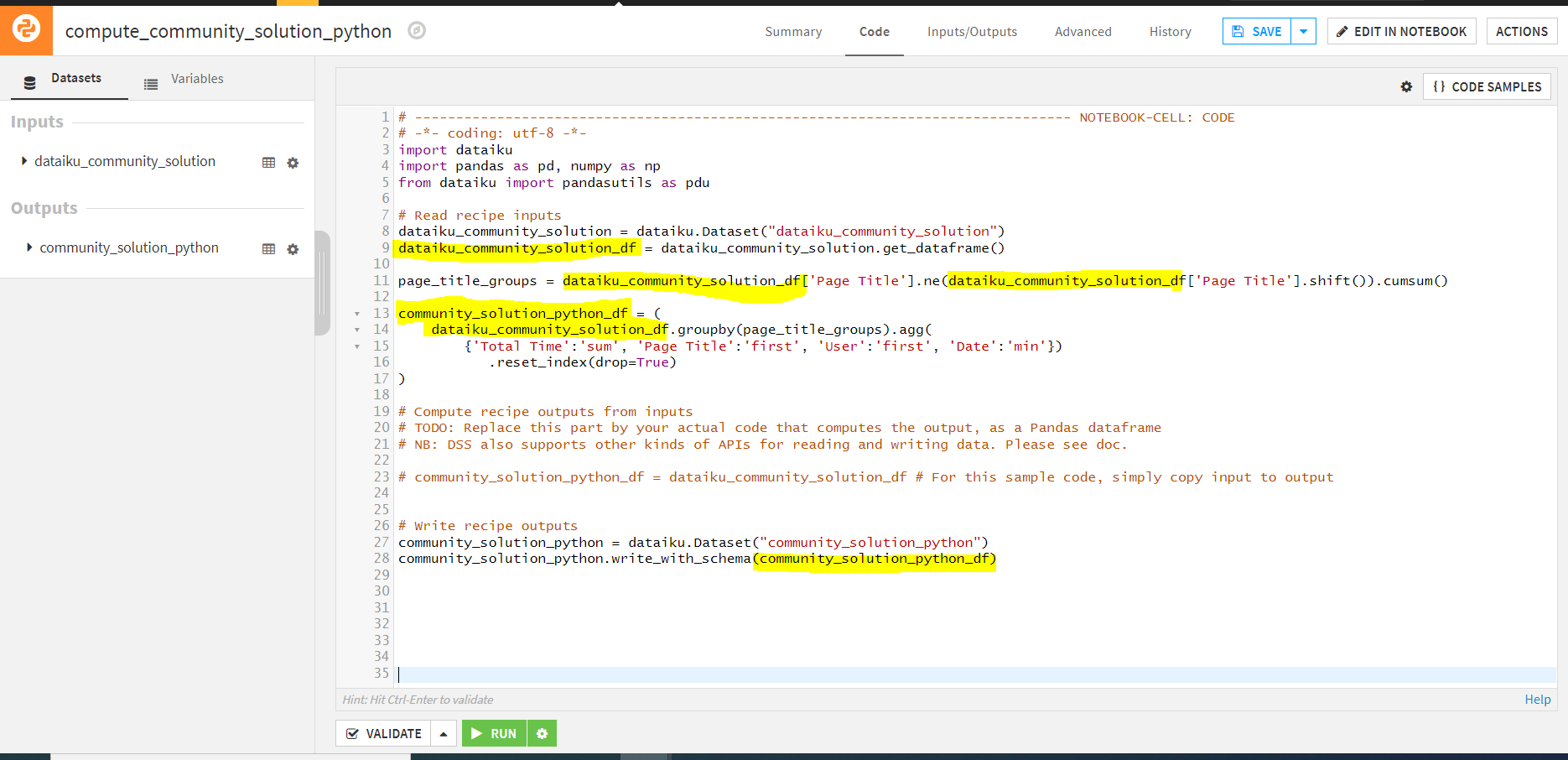
Important to note you have to adjust the code for every 'dataiku_community_solution' and 'community_solution_python'. These are the names of my original & output datasets. I've highlighted in the screenshot to where you can find the original and output datasets in lines 9 and 28. Also, if you want to include the minimum time stamp in python recipe you can add , 'Time stamp':'min' to line 15.
LMK if you run into any trouble!
# -------------------------------------------------------------------------------- NOTEBOOK-CELL: CODE
# -*- coding: utf-8 -*-
import dataiku
import pandas as pd, numpy as np
from dataiku import pandasutils as pdu
# Read recipe inputs
dataiku_community_solution = dataiku.Dataset("dataiku_community_solution")
dataiku_community_solution_df = dataiku_community_solution.get_dataframe()
page_title_groups = dataiku_community_solution_df['Page Title'].ne(dataiku_community_solution_df['Page Title'].shift()).cumsum()
community_solution_python_df = (
dataiku_community_solution_df.groupby(page_title_groups).agg(
{'Total Time':'sum', 'Page Title':'first', 'User':'first', 'Date':'min'})
.reset_index(drop=True)
)
# Compute recipe outputs from inputs
# TODO: Replace this part by your actual code that computes the output, as a Pandas dataframe
# NB: DSS also supports other kinds of APIs for reading and writing data. Please see doc.
# community_solution_python_df = dataiku_community_solution_df # For this sample code, simply copy input to output
# Write recipe outputs
community_solution_python = dataiku.Dataset("community_solution_python")
community_solution_python.write_with_schema(community_solution_python_df)
Hello,
One solution is to do the following operations :
1. For each row get the "Page" of the previous row (assuming your dataset is already sorted)
2. Compare the pages of the two rows
3. Add a new column that says whether you changed page at that row
4. Do the cumulative sum of this column
5. Group by on the cumulative sum (i.e. page change index)
If doing it in a python recipe/notebook it will look like that:
## Check if you have the same page as above
input_df["same_page"] = input_df["Page"].shift(1) != input_df["Page"]
## Do the cumulative sum
input_df["PageChangeIndex"] = input_df["same_page"].cumsum(axis=0,skipna=True)
## Group by the page change index, sum time and keep the page name
output_df = input_df.groupby(["PageChangeIndex"]).agg({"Page": "first", "Time": "sum"}).reset_index()
Otherwise you can do the step 1. in a Window visual recipe, step 2. and 3. in a prepare recipe, step 4. in a python recipe and step 5. in a group by visual recipe
I hope it helps,
Arnaud


{kind=link}
{kind=link}