Sign up to take part
Registered users can ask their own questions, contribute to discussions, and be part of the Community!
Registered users can ask their own questions, contribute to discussions, and be part of the Community!
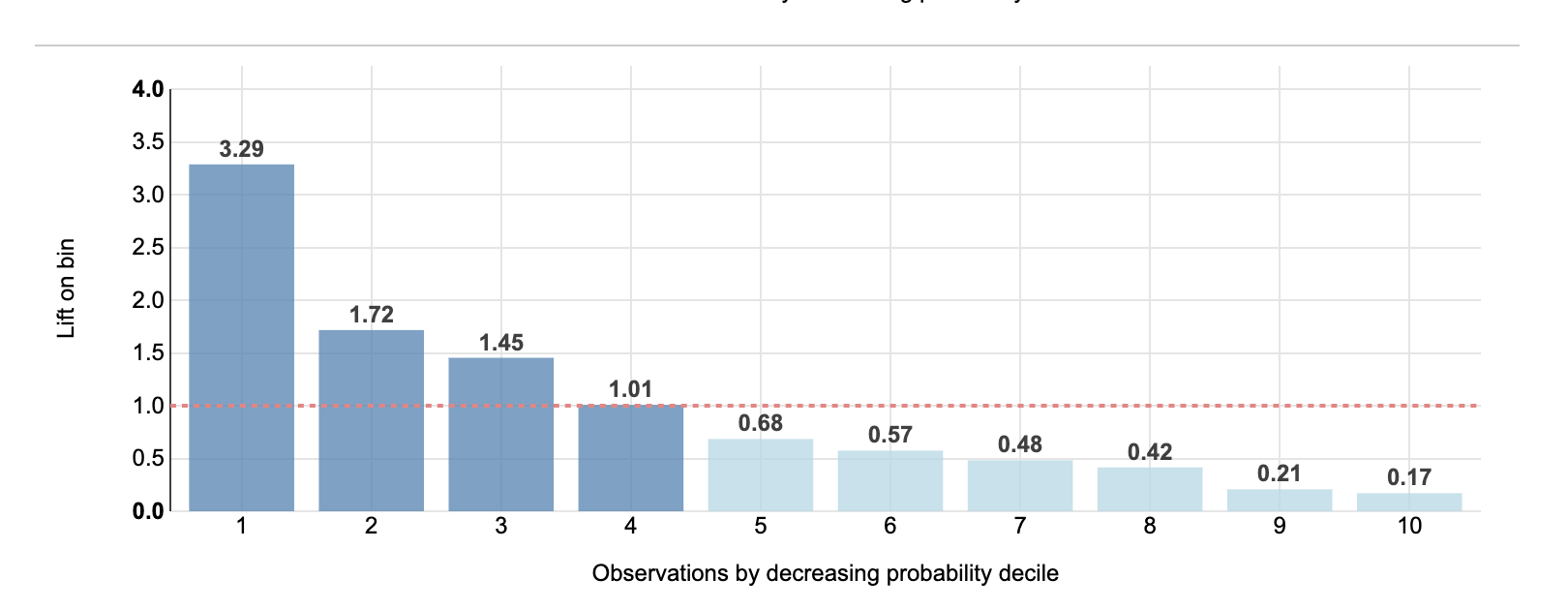
Currently I'm using Lift as a metric to evaluate a classification model in the DI Lab. The lift is a great indicator of the performance of the model on different observations per bin (observations sorted by deciles of decreasing predicted probability). I was wondering to what extend you can deploy this on your population. So for example if the lift in the first three bins of the testset is larger dan 1.
Can I assume that in the population on which you score the model on it make sense to use these bins as well? So use only the upper 30% of the sorted decreasing probability? And are there downsides to consider?
Hi,
This is an interesting question.
Usually the right quantile for your Lift score depends on how your predictions will be used in real life. For instance, imagine that you are developing a fraud detection system. Your model predictions will be used by a team of human experts to prioritize their manual inspection. Now if that team can only inspect 10% of cases, your model should be optimized for the lift at 10%. The same reasoning can be applied to other use cases like marketing campaign optimization (see this great explanation) or predictive maintenance.
Now if you want to deploy your model on a new population which differs from the one you used for training, that's another challenge. Whatever the metric you use, if you have a "drift" in your test data, the performance will be lower.
First of all, it's important to test for potential drift whenever scoring a new dataset. I recommend using our new plugin for model drift: https://www.dataiku.com/product/plugins/model-drift-monitoring/ which provides not only a drift score, but also various charts to interpret what exactly has drifted.
Hope it helps,
Alex
Hi,
This is an interesting question.
Usually the right quantile for your Lift score depends on how your predictions will be used in real life. For instance, imagine that you are developing a fraud detection system. Your model predictions will be used by a team of human experts to prioritize their manual inspection. Now if that team can only inspect 10% of cases, your model should be optimized for the lift at 10%. The same reasoning can be applied to other use cases like marketing campaign optimization (see this great explanation) or predictive maintenance.
Now if you want to deploy your model on a new population which differs from the one you used for training, that's another challenge. Whatever the metric you use, if you have a "drift" in your test data, the performance will be lower.
First of all, it's important to test for potential drift whenever scoring a new dataset. I recommend using our new plugin for model drift: https://www.dataiku.com/product/plugins/model-drift-monitoring/ which provides not only a drift score, but also various charts to interpret what exactly has drifted.
Hope it helps,
Alex

{kind=link}