Sign up to take part
Registered users can ask their own questions, contribute to discussions, and be part of the Community!
Registered users can ask their own questions, contribute to discussions, and be part of the Community!
Hi,
I was creating a plugin in order to correct a weird behavior of one of our engine : while syncing a Teradata table to HDFS using the TDCH engine, dates (in a "%Y-%m-%D" format) are imported as dates in the schema even though they are strings.
I created a plugin recipe that copy the synced HDFS dataset to another using spark and modify the schema of our new dataset using the API in order to set the dates to string (which is the real format of our data) .
The plugin didn't work because of multiple reasons :
So I thought it was maybe due to the fact that I had specified the pyspark version (to 2.4.0) in the root folder and in the code-env/specs/python/requirements.txt.
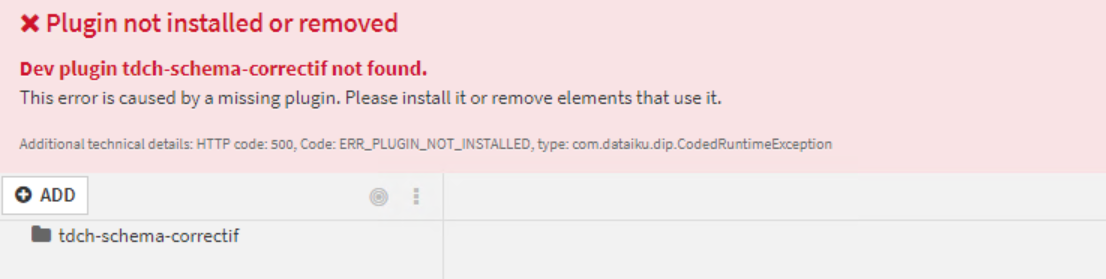
Here I commented all my lines in my "requirements.json" in order to check the effect of this one because it was the first time I was using it and here the bug happened:
In conclusion : the plugin still exists with everything but cannot be accessed due to the requirements.json being empty.
I tried to access it by modifying the url address but the editor isn't available.
Below the json and the plugin recipe.
requirements.json :
//{
// "python" : [
// {"name":"pyspark", "version":"==2.4.0"}
//],
//"R" : [
//]
//}
recipe.py :
# -*- coding: utf-8 -*-
from dataiku.customrecipe import *
import dataiku
import numpy as np
import pyspark
from dataiku import spark as dkuspark
from pyspark import SparkContext
from pyspark.sql import SQLContext
### débuter notre session spark
print('creating session')
sc = SparkContext().getOrCreate()
sqlContext = SQLContext(sc)
print('session created')
### récupérer notre dataset d'input (dataset + df) et le dataset d'output
# input
to_correct = get_input_names_for_role('to_correct')[0] # notre dataset qui va être corrigé
dataset_to_correct = dataiku.Dataset(to_correct) # Récupérer le dataset d'input rapidement grâce à spark
print('getting dataframe')
df = dkuspark.get_dataframe(sqlContext, dataset_to_correct) # le dataframe spark
print('df get')
#output
output_name = get_output_names_for_role('main_output')[0].split('.')[-1] # notre dataset de sorti
dataset_out = dataiku.Dataset(output_name)
dkuspark.write_with_schema(dataset_out, df) # écrire le dataframe (copie à l'identique)
# testé : 1.33 min afin de lancer spark + écrire un df[100000,804]
### Modifier le dataset afin d'obtenir les variables dates en string
# init
client = dataiku.api_client()
projectkey = dataiku.get_custom_variables().get('projectKey')
project = client.get_project(projectkey)
dataset = project.get_dataset(output_name) # pas le même type de dataset, attention
# Récupérer notre schéma
schema = dataset.get_schema() # au cas où l'on ai une erreur
new_schema = dataset.get_schema() # celui que l'on va modifier
for i in range(len(new_schema['columns'])) : # pour chaque colonne de notre schema
column = new_schema['columns'][i] # notre colonne en cours
if column['type'] == u'date' : # si nous avions une date à la base
new_schema['columns'][i]['type'] = u'string' # modifier notre date en string afin que Dataiku l'affiche dans l'explore
# Une fois toutes les modifications effectuées, les enregistrer au sein du dataset
result = dataset.set_schema(new_schema)
# ici un dictionnaire avec les résulats de nos modifications
resultat = dict()
resultat['dataset_name'] = output_name # le nom du dataset modifier
resultat['result'] = result # est-ce que le traitement à correctement fonctionné
resultat['old_schema'] = schema # l'ancien schema au sein de notre dataset
if True in (result['error'], result['fatal']) : # si on a une erreur
print("La modification du schéma a échoué. Re-modification à l'état original")
resultat['new_schema'] = schema
resultat['presence_erreur'] = True
dataset.set_schema(schema) # remettre le schema d'origine
else : # si tout s'est déroulé correctemnt
resultat['new_schema'] = new_schema
resultat['presence_erreur'] = False
print("Ici les modifications effectuées :\n%s" % resultat)
Greetings
I just wanted to inform you about this bug.
To solve it : either you delete the plugin folder from the machine or using the command line, modify the requirements.json (un-commenting the corresponding lines)

{kind=link}
{kind=link}
{kind=link}